해시(Hash)
해시(Hash) 관련 개념 정리글 입니다.
해시는 효율적인 데이터 저장과 검색을 위해 사용되는 자료 구조로, 다양한 응용 분야에서 활용된다.
해시의 개념
- 해시는 효율적인 데이터 저장과 검색을 위해 사용되는 데이터 구조이다. 해시 함수를 통해 데이터를 고정된 크기의 해시 코드로 매핑하고, 이를 인덱스로 사용하여 데이터를 저장하고 검색한다.
해시 테이블의 구조
해시 함수 (Hash Function): 해시 테이블에서 가장 중요한 구성 요소로, 입력된 키를 해시 코드로 변환하는 역할을 한다. 해시 함수는 키의 고유한 특성을 활용하여 해시 코드를 생성하며, 이 해시 코드를 인덱스로 사용하여 데이터를 저장하고 검색한다.
해시 테이블 배열 (Hash Table Array): 해시 테이블은 배열 형태로 구현되며, 데이터를 저장하는 버킷(bucket)의 집합이다. 각 버킷은 해시 코드에 대응하는 인덱스로 접근할 수 있고, 각 버킷에는 키-값 쌍이 저장된다.
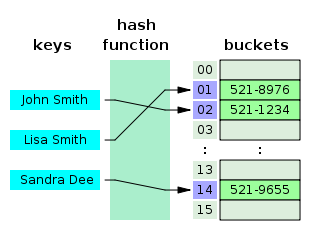
해시 테이블의 충돌 해결
해시 함수는 입력 데이터의 개수가 해시 테이블 배열의 크기보다 큰 경우, 서로 다른 입력이 동일한 해시 코드를 가질 수 있다. 이를 충돌이라고 한다.
1. Separate Chaining (분리 연결법)
- Separate Chaining은 해시 테이블의 각 버킷이 연결 리스트로 구현된 충돌 해결 방법이다. 충돌이 발생할 경우 (즉, 여러 개의 키가 동일한 인덱스로 해시되는 경우), 동일한 해시 코드를 가진 키-값 쌍은 해당 인덱스와 연결된 연결 리스트에 저장된다.
- 장점
- 적재율이나 해시 함수에 대해 별로 신경 쓰지 않아도 되고 구현이 간단하다.
- 계속 체인으로 연결하기 때문에 공간사용이 유연하여 해시 테이블의 포화상태가 없다.
- 단점
- 사용하지 않고 남는 공간이 있기 때문에 메모리가 낭비된다.
- 체인의 길이가 너무 길어지면 탐색이 \(O(n)\)이 되어 해시의 장점을 이용하지 못한다.
- LinkedList를 사용하여 저장하므로 캐시의 성능이 저하됩니다.(Open Addressing은 캐시 성능이 좋다.)
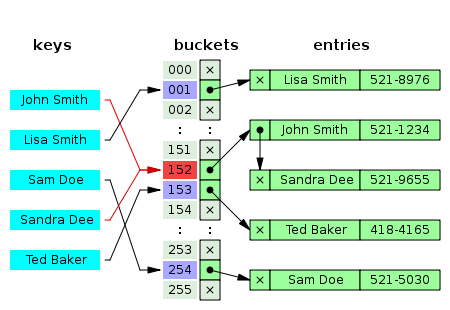
Separate Chaining (분리 연결법)
2. 개방 주소법(Open Addressing)
- Open Addressing은 chaining과 달리 한 공간에 들어갈 수 있는 개수가 제한되어 있어 알고리즘을 반복해 비어있는 공간을 계속 찾는 방법이다. 메모리를 낭비하지 않지만 해시 충돌이 일어나므로 알고리즘 선택에 주의해야 한다.
1. 선형 탐사(Linear Probing)
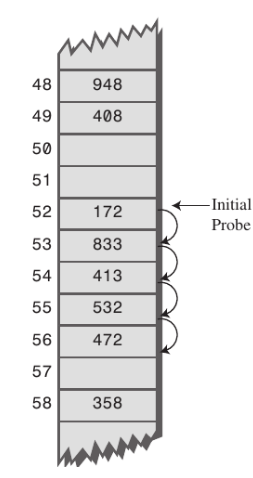
- 선형탐사(Linear Probing)는 최초 저장되는 공간에 값이 있으면 비어있는 공간이 나올 때까지 1씩 이동하여 탐색한다.
- 하지만 primary clustering 문제가 발생하는데, 한 번 충돌하기 시작하면 해당 지역은 계속 충돌이 발생한다.
- 평균 검색시간이 너무 늘어나기 때문에 해시의 성능을 효율적으로 이용할 수 없다.
2. 제곱탐사(Quadratic Probing)
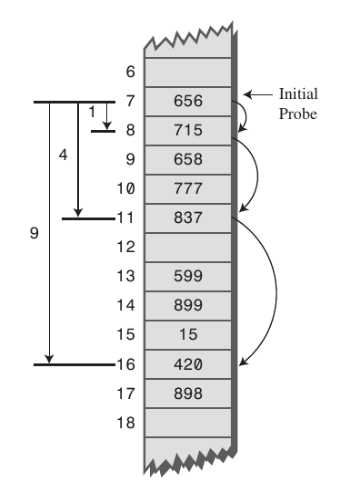
- 제곱탐사(Quadratic Probing)는 해시의 저장순서 폭을 제곱으로 저장하는 방식이다. 예를 들어 처음 충돌이 발생한 경우에는 1만큼 이동하고 그 다음 계속 충돌이 발생하면 \(2^{2}\), \(3^{2}\)씩 칸씩 옮기는 방식이다.
- 하지만 이 방법은 secondary clustering 단점이 있는데 처음에 같은 해시 값이 나온다면, i값에 따라서 해시 값이 바뀌기 때문에 선형탐사와 같이 계속 충돌이 반복적으로 발생한다.
3. 이중 해싱(Double hashing)
\[h(k,i) = (h_1(k) + i \times h_2(k)) \, mod \, m\]
- 이중 해싱(Double hashing)은 2개의 해시 함수를 이용하는 동시에 횟수가 늘어날 때마다 i값을 증가시켜서 독립적인 해시 값을 가지는 방법이다. 선형탐사, 제곱 탐사에서 각각 발생하는 primary clustering, secondary clustering의 문제를 모두 해결할 수 있다.
- 해시 함수에 따라 성능이 달라지는데 \(h_2(k)\) 함수는 해시 테이블 크기 \(m\)과 서로소여야 합니다. \(m\)을 소수로하고 \(h_2(k)\)이 \(m\)보다 작은 정수이어야 한다.
개방 주소법(Open Addressing)에서 데이터를 삭제하면 삭제된 공간은 Dummy Space로 활용되는데, 그렇기 때문에 해시 테이블을 재정리 해주는 작업이 필요하다고 한다.
해시의 장단점
- 장점
- 빠른 데이터 접근: 해시 테이블을 사용하면 키를 기반으로 데이터를 빠르게 찾을 수 있다. 해시 함수를 통해 키를 해시 코드로 변환하고, 이 코드를 사용하여 데이터가 저장된 위치를 찾을 수 있다.
- 효율적인 데이터 저장 및 검색: 해시 테이블은 키-값 쌍을 저장하고 검색하는 데 효율적이다. 충돌이 발생하지 않는 한, 평균적으로 \(O(1)\)의 시간 복잡도로 데이터를 검색할 수 있다.
- 고유한 키 값: 해시 함수를 사용하면 고유한 키 값을 생성할 수 있다. 이를 통해 데이터의 식별에 용이하며, 중복된 값을 가지는 경우에도 충돌 해결 방법을 통해 데이터를 정확하게 찾을 수 있다.
- 단점
- 충돌 가능성: 서로 다른 키가 동일한 해시 코드를 가질 수 있다. 충돌은 해시 함수의 성능에 영향을 미치며, 적절한 충돌 해결 방법을 사용하여 처리해야 한다.
- 메모리 요구량: 해시 테이블은 모든 키-값 쌍을 저장하기 위한 메모리를 필요로 한다. 큰 데이터 세트의 경우, 충분한 메모리가 필요할 수 있다.
- 해시 함수의 성능: 해시 함수의 선택은 해시의 성능에 큰 영향을 미친다. 충돌을 최소화하고 균일한 해시 코드 분포를 얻기 위해 적절한 해시 함수를 선택해야 한다.
해시 테이블의 시간복잡도
- 각각의 Key값은 해시함수에 의해 고유한 index를 가지게 되어 바로 접근할 수 있으므로 평균 \(O(1)\)의 시간복잡도로 데이터를 조회할 수 있다.
- 하지만 데이터의 충돌이 발생한 경우 Chaining에 연결된 리스트들까지 검색을 해야 하므로 \(O(n)\)까지 시간복잡도가 증가할 수 있다.
해시의 응용 분야
- 검색 및 조회: 해시를 사용하면 키를 기반으로 데이터를 빠르게 검색하고 조회할 수 있다. 데이터베이스, 캐시 시스템, 색인 구조 등에서 많이 활용된다.
- 데이터베이스 인덱싱: 해시를 사용하여 데이터베이스의 인덱스를 구성하면 데이터 검색 속도를 향상시킬 수 있다.
- 보안 및 암호화: 해시 함수는 데이터의 무결성 검증, 암호화, 디지털 서명 등 보안 관련 작업에 사용된다.
- 캐싱: 해시를 사용하여 캐시 시스템을 구현하면 데이터 접근 속도를 향상시킬 수 있다.
- 분산 시스템: 해시 함수를 사용하여 데이터를 분산시키고 분산 시스템에서 데이터의 로드 밸런싱을 수행할 수 있다.
