너비 우선 탐색(BFS)
너비 우선 탐색(BFS) 관련 개념 정리글 입니다.
BFS는 주로 네트워크 라우팅, 최단 경로 문제, 그래프에서의 연결 여부 판별 등 다양한 분야에서 활용한다.
BFS의 개념과 특징
개념
- BFS는 그래프 탐색 알고리즘 중 하나로, 그래프의 모든 노드를 방문하거나 원하는 조건을 만족하는 노드를 찾을 때 사용된다.
- 시작 노드에서 인접한 노드들을 모두 방문한 후, 그 다음 인접한 노드들을 탐색하는 방식으로 동작한다.
특징
- 레벨 순서 탐색: 시작 노드에서부터 거리에 따라 레벨별로 탐색. 즉, 먼저 인접한 노드들을 모두 방문한 후에, 그 다음 레벨의 노드들을 방문
- 최단 경로 탐색: 시작 노드에서 목표 노드까지의 최단 경로를 찾을 때 주로 사용
- 큐(Queue) 사용: BFS는 큐 자료구조를 사용하여 구현된다. 시작 노드를 큐에 넣고, 인접한 노드들을 큐에 차례로 추가하면서 탐색을 진행한다.
- 방문한 노드 표시: 이미 방문한 노드는 다시 방문하지 않도록 표시 (무한 루프 방지)
BFS의 동작 원리
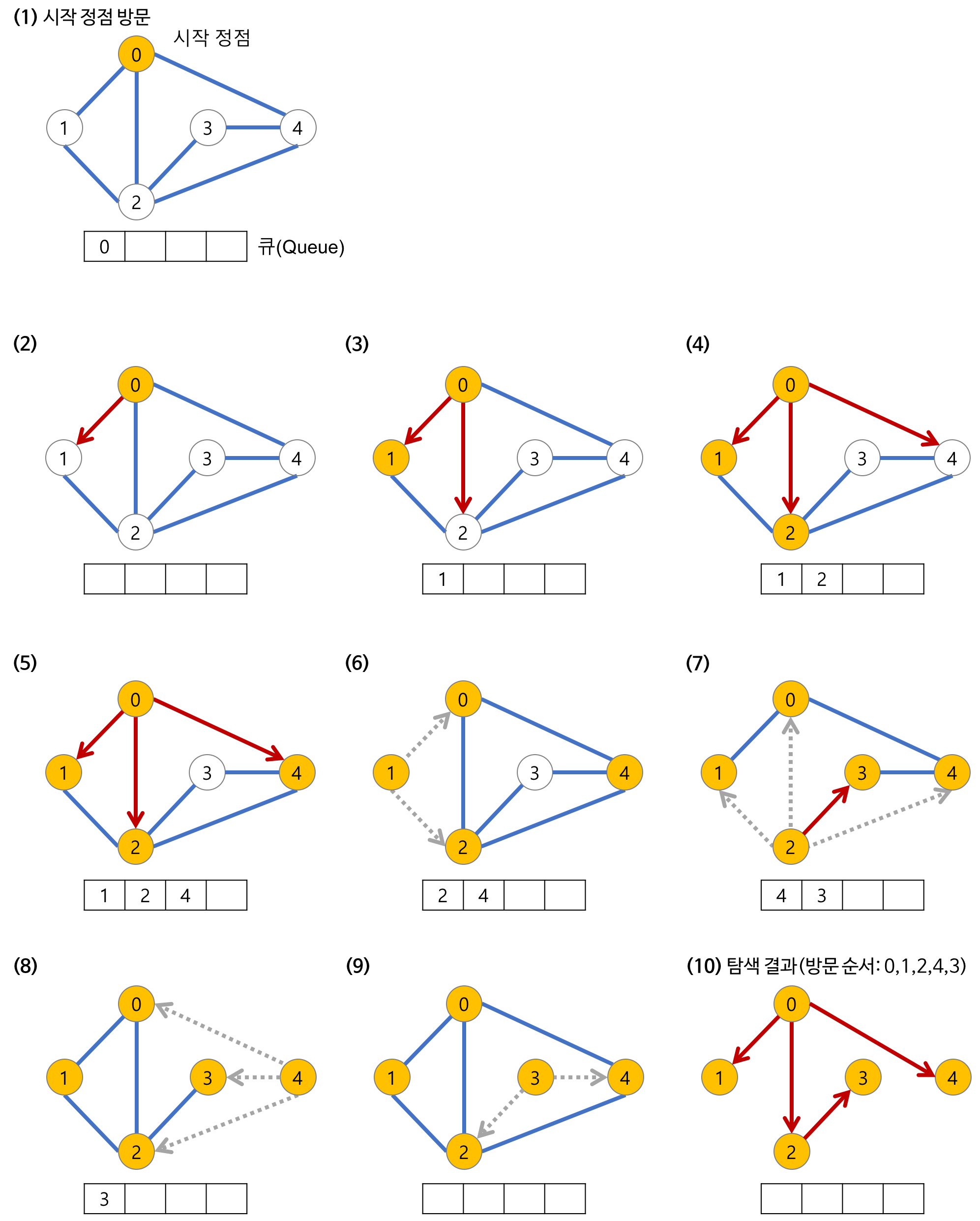
BFS 동작 원리
- 시작 노드 선택 및 큐 초기화
- 탐색을 시작할 노드를 선택 (시작 노드)
- 큐(Queue) 자료구조를 생성하고, 시작 노드를 큐에 넣는다.
- 큐에서 노드 추출 및 탐색
- 큐에서 노드를 하나 꺼내고, 해당 노드를 방문한 것으로 표시
- 해당 노드와 인접한 모든 미방문 노드들을 큐에 순서대로 추가
- 큐가 빌 때까지 반복
- 큐에서 노드를 하나씩 꺼내서 탐색하고, 그 노드의 인접 미방문 노드들을 큐에 추가
- 큐가 빌 때까지 이 과정을 반복
- 탐색 종료
- 큐가 더 이상 노드를 포함하지 않을 때까지 반복하면 모든 노드가 탐색된다.
- 모든 노드를 방문한 후에는 탐색 종료
BFS의 핵심 아이디어는
인접한 노드들을 큐에 넣고 먼저 처리하면서 탐색하는 것으로, 너비 우선적인 탐색을 수행
BFS의 구현 방법
큐를 이용한 방법
from collections import deque def bfs_queue(graph, start): visited = set() queue = deque([start]) while queue: node = queue.popleft() if node not in visited: print(node, end=' ') # 노드 처리 (출력) visited.add(node) queue.extend(graph[node] - visited) # 그래프는 딕셔너리 형태로 표현 graph = { 'A': {'B', 'C'}, 'B': {'A', 'D', 'E'}, 'C': {'A', 'F'}, 'D': {'B'}, 'E': {'B', 'F'}, 'F': {'C', 'E'} } start_node = 'A' print("BFS using Queue:") bfs_queue(graph, start_node)큐를 사용한 BFS 구현
재귀를 이용한 방법
def bfs_recursive(graph, queue, visited): if not queue: return node = queue.pop(0) if node not in visited: print(node, end=' ') # 노드 처리 (출력) visited.add(node) queue.extend(graph[node] - visited) bfs_recursive(graph, queue, visited) # 그래프는 딕셔너리 형태로 표현 graph = { 'A': {'B', 'C'}, 'B': {'A', 'D', 'E'}, 'C': {'A', 'F'}, 'D': {'B'}, 'E': {'B', 'F'}, 'F': {'C', 'E'} } start_node = 'A' print("\nRecursive BFS:") bfs_recursive(graph, [start_node], set())재귀적인 BFS 구현
비교
큐를 사용한 BFS는 일반적으로 메모리를 효율적으로 사용하며, 모든 노드를 방문하는 데 적합한 방식
재귀적인 BFS는 파이썬에서의 재귀 제한에 영향을 받을 수 있으며, 큰 그래프에서는 스택 오버플로우가 발생할 수 있다.
BFS의 시간 복잡도 분석
노드 수: \(V\) (Vertices)
간선 수: \(E\) (Edges)
BFS는 모든 노드와 간선을 한 번씩만 검사하므로, 노드와 간선의 수에 선형적으로 영향을 받는다.
큐를 사용한 BFS 시간 복잡도:
- 큐에 노드를 삽입하는 시간 복잡도: \(O(1)\)
- 각 노드를 방문하고 큐에서 제거하는 시간 복잡도: \(O(1)\)
- 총 노드 수 \(V\)에 대해 모든 노드를 방문하고 간선을 검사하므로, 시간 복잡도는 \(O(V + E)\)
재귀적인 BFS 시간 복잡도:
- 재귀 호출을 통한 노드 방문과 처리: \(O(1)\)
- 재귀 호출을 통해 노드와 간선을 검사하므로, 시간 복잡도는 \(O(V + E)\)
최악의 경우 그래프가 완전 그래프인 경우, 간선의 수 \(E\)는 \(V * (V - 1) / 2\)로 나타낼 수 있다. 따라서 최악의 경우
시간 복잡도는 \(O(V^2)\)가 될 수 있다.일반적으로 노드 수와 간선 수에 비례하는 \(O(V + E)\) 시간 복잡도를 가지므로, BFS는 그래프 탐색에서 효율적인 알고리즘 중 하나이다.
BFS의 활용 예시
최단 경로 찾기: BFS는 가중치가 없는 그래프에서 최단 경로를 찾는 데 사용된다. (노드 간 거리가 모두 동일한 경우에 특히 유용)
네트워크 탐색: 네트워크 혹은 그래프 구조에서 모든 노드를 탐색하거나 연결된 노드를 찾는 데 사용된다.
게임 상태 공간 탐색: 보드 게임이나 퍼즐과 같은 상태 공간을 탐색할 때, 가능한 모든 경로를 탐색하는 데 사용된다.
BFS 장단점
BFS의 장점
- 최단 경로 보장: 가중치가 없는 그래프에서 모든 가중치가 동일한 경우, BFS는 최단 경로를 보장
- 단계별 탐색: 노드의 인접한 레벨부터 탐색하기 때문에, 레벨별 탐색을 통해 문제를 단계적으로 해결할 수 있다.
- 네트워크 탐색: 네트워크에서 모든 노드를 탐색하는 데 사용할 수 있다.
BFS의 단점:
- 메모리 사용량: 큐에 모든 노드를 저장해야 하므로, 메모리 사용량이 크게 증가할 수 있다.
- 최단 경로 이외 탐색: 모든 경로를 탐색하므로, 목표지점에 도달한 경로 이외의 경로도 탐색할 수 있다.
BFS와 DFS 비교
| 비교 요소 | BFS | DFS |
|---|---|---|
| 탐색 방식 | 인접한 모든 노드를 먼저 탐색 | 한 경로를 최대한 깊게 탐색한 후 다른 경로로 이동 |
| 구현 | 큐를 사용하여 구현 | 스택이나 재귀를 사용하여 구현 |
| 경로 | 최단 경로를 보장 | 최단 경로를 보장 X |
| 메모리 사용 | 메모리 사용량이 더 많다 | 메모리 사용량이 더 적음 |
| 적합한 상황 | 최단 경로나 모든 가능한 경로를 탐색 | 깊게 파고들어야 하는 문제나 해를 찾는 문제 |
BFS와 DFS 특징 비교
