1주차 | Python
KT AIVLE SCHOOL 5기 1주차에 진행한 Python 강의 내용 정리 글입니다.
- Jupyter notebook
- 자료형(List, Dictionary, Tuple)
- 흐름 제어(조건문과 반복문)
- 함수 생성 및 활용
- 데이터 분석/모델링을 위한 데이터 구조
- Numpy 기초
- 판다스(Pandas)
- 출처
Jupyter notebook
- 셀 전환 방법
- 마크 다운으로 전환 :
m - 코드 셀로 전환 :
y
- 마크 다운으로 전환 :
- 코드 셀 라인 번호 표시
- 셀 선택 후
Shift + L⇒ 밑의 모든 셀에도 적용됨
- 셀 선택 후
- 참고 링크
https://gist.github.com/ninanung/2b81a5db946c26c98c573e3662a92b62
자료형(List, Dictionary, Tuple)
- 리스트(List)
- 리스트는 여러 값을 하나의 변수로 저장
- 실전에서는 분석/모델링 할 때 사용하기 보다는, 임시 저장소 같은 역할로 자주 사용
- 딕셔너리(Dictionary)
- 딕셔너리는 여러 형태의 자료형을 하나로 묶어 준다 (종합 선물 세트)
- 실전에서는
- 데이터 프레임을 만들 때, 딕셔너리를 변환
- 어떤 함수의 실행 결과가 딕셔너리 형태인 경우, 저장해서 조회용으로 사용
- JSON 형식이 파이썬에서는 딕셔너리와 호환
- 튜플(tuple)
- 튜플은
좌표, 순서쌍을 담는 자료형
- 튜플은
# 자료형
## 1. 리스트(List)
list(range(1, 12, 2)) # 리스트 안에 리스트 저장 가능
print(a[2:5]) # 2 ~ 4번 인덱스
print(a[2:]) # 2 ~ 끝까지
print(a[-3:]) # 뒤에서 세번째에서 끝까지
del a[2] # 인덱스로 삭제
a.remove(45) # 값으로 삭제
# 리스트로 부터 값 할당
a = [23, 3, 16]
a1, a2, a3 = a
## 2. 딕셔너리(dictionary)
dict_a.items() # key와 값을 쌍(tuple)으로 조회
del dict_a['v2'] # 삭제
# 딕셔너리로 부터 값 할당
dict_a = { 'v1': 32, 'l1': [1,2,3], 'd1': {'a':1, 'b':2}}
# 각 값을 할당
a1, a2, a3 = dict_a.values()
흐름 제어(조건문과 반복문)
- Bool 연산자
- 조건 제어(if - else 문)
- 반복 제어
for looprange, list, dictionary등 으로부터 순서대로 값을 뽑고, 코드를 반복 수행- 종료 조건:
range, list, dictionary의 값을 모두 추출했을 때,break를 만났을 때
while loopfor loop와 사용법과 용도는 거의 유사- 차이점
- 조건 변경문이 들어가야 함
- 종료 조건: 조건문이
False일 때,break를 만났을 때
무한 반복 & break
- 반복 횟수가 정해지지 않을 때는
while사용, 횟수가 정해져 있으면for
# 흐름 제어
## 1. 조건 제어
math, korean, history=80, 70, 75
if (math < 70) or (korean < 70) or (history < 70): # or: |, and: &
print('fail')
else:
print('pass')
## 2. 반복 제어
total = 0
for i in range(1,101): # 모듈로 : 나머지, // : 몫
if i % 2 == 1:
total += i
print(total)
multiple7 = [n for n in range(1, 101) if n % 7 == 0] # 리스트 컴프리헨션
dict_a = { 'v1 ' : 32, 'l1' : [1, 2, 3], 'd1' : {'a' : 1, 'b' : 2}}
for key, value in dict_a.items():
print('key : ', key)
print('value : ', value)
## 3. 복습 문제: 소수 출력 - 에라토스테네스의 체 이용
#1부터 100까지 수 중, 소수(prime number)를 제외한 모든 수를 출력
### 내 풀이
n = 100
array = [True] * (n+1)
for i in range(2, n + 1):
if array[i]:
j = 2
while i * j <= n:
array[i * j] = False
j +=1
for i in range(2, n + 1):
if not array[i]:
print(i, end = ',')
### 답안
# 소수가 아닐떄만 바로 출력 (자신보다 작은 수로 나누어 떨어지는 경우)
for i in range(3, 101) :
for j in range(2, i) :
if i % j == 0 :
print(i)
break
에라토스테네스의 체 (N보다 작거나 같은 모든 소수 찾을 떄)
- 2부터 N까지의 모든 자연수를 나열한다
- 남은 수 중에서 아직 처리하지 않은 가장 작은 수 i를 찾는다
- 남은 수 중에서 i의 배수를 모두 제거한다(i는 제거하지 않는다)
- 더 이상 반복할 수 없을 때까지 2번과 3번 과정을 반복한다.
함수 생성 및 활용
함수를 만드는 두 가지 목적
- 복잡한 코드 단순화
- 특정 기능 (function)별로 모듈화
함수의 구성 요소
- Input
- 입력 매개변수
- 생략 가능
- 처리
- 예외 처리
try: 오류를 감지하고자 하는 코드 블럭except오류 유형: 발생된 오류를 처리
- 예외 처리
- Output
- 실행 결과
- 생략 가능
#함수
## 1. Input
def hello(name, loud = 1) :
if loud == 1 :
print('HELLO ' + name + ' ~!!!')
else :
print('Hello ' + name + ' ~~~')
hello(name = 'Han', loud = 0) # 매개변수 이름과 입력값
hello(name = 'Han') # 기본값 지정 매개변수 생략
hello('Han') # 기본값 지정 매개변수 생략
hello('Han',0) # 입력매개변수 이름 생략
hello(loud = 0, name = 'Han') # 입력값 순서 바꾸기
def numbers(*nums) : # 입력값의 갯수를 제한하지 않고 받고자 할 때 '*' 사용
print(nums, type(nums))
numbers(1, 2, 3)
numbers(2, 4, 6, 8, 10)# 입력된 데이터 타입은 tuple
## 2. Output
def calculator(a, b) :
summ = a + b
mult = a * b
return summ, mult
r1, r2 = calculator(10, 5)
print(r1, r2)
r1, _ = calculator(10, 5) # 하나의 결과만 필요하다면
b = calculator(1, 3)
print(b, type(b)) # 여러개의 결과를 하나로 받으면 튜플 형태로 받음
## 3. 예외 처리
def divide(a, b) :
try :
result = a / b
return result
except ZeroDivisionError:
print("0으로 나눌수 없습니다.")
divide(10, 0)
## 4. 복습 문제
# 기념일 계산기
from datetime import datetime
def date_check(year, month, day):
try:
year = int(year)
month = int(month)
day = int(day)
date = datetime(year, month, day)
return date
except ValueError as e:
print("올바른 날짜 형식으로 입력해주세요.")
return None
def date_count(today):
birthday = date_check(2021, 12, 2)
d_day = today - birthday
return print('오늘은 ', d_day.days, '일째 입니다!')
today = datetime.now()
date_count(today)
데이터 분석/모델링을 위한 데이터 구조
CRISP-DM (데이터 분석 방법론)
- 암기(중요)
- 거의 모든 데이터 분석 및 ML/DL 관련 프로젝트들의 흐름
면접 질문에서 나올정도로 중요함
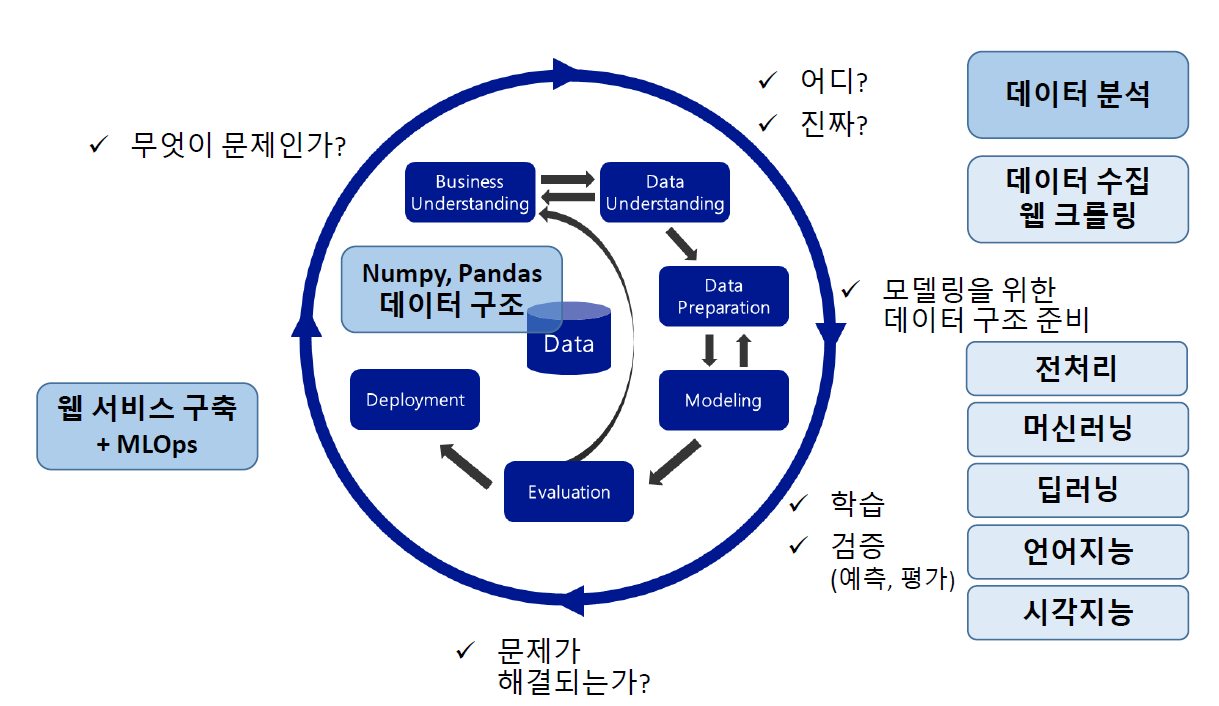
- Business Understanding(비즈니스 이해): 비즈니스의 문제를 이해하고 정의하는 단계
비즈니스 관점(도메인 지식)이 매우 중요
- Data Understanding (데이터 분석, 이해): 데이터 분석 단계, 가설
- Data Preparation (데이터 전처리)
- Modeling (ML/DL)
- Evaluation (평가): 문제가 해결되었는지 확인
- Deployment (배포)
분석할 수 있는 데이터
- 분석할 수 있는 정보의 종류 2가지
- 숫자 : 연산 가능하면 수치형
- 연속형 : 온도
- 이산형 : 판매량, 매출액, 나이
- 범주 : 묶음 (묶음 안에 공통된 특징 존재), 대체로 우리가 결정해서 만들어냄
- 명목형 : 성별, 시도
- 순서형 : 연령대, 매출 등급
- 숫자 : 연산 가능하면 수치형
- 두 가지 동류의 정보가 특별한 구조를 가져야 함
- 기본 구조: 2차원
- 행:
분석 단위,데이터 한 건, 한 건→데이터가 많다 (데이터 행의 수가 많다), 사이즈가 크다 (행과 열 포함 크다)- 행이 어떤 단위인지 정하고 알아내는 과정이 중요함
- 열:
정보, 변수, 요인 (x, feature), 결과 (y, target, label)
- 행:
- 기본 구조: 2차원
- (분석, 모델링을 위한) 데이터 구조를 다루는 패키지
Numpypandas
Numpy 기초
배열 만들기
- 데이터 분석에서는 →
수학적 계산이 가능하고대량의 데이터 처리가 빨라야 한다 - 형태(크기) 확인
shape속성으로 배열 형태를 확인axis: 배열의 각 축rank: 축의 개수(차원)shape: 축의 길이, 배열의 크기
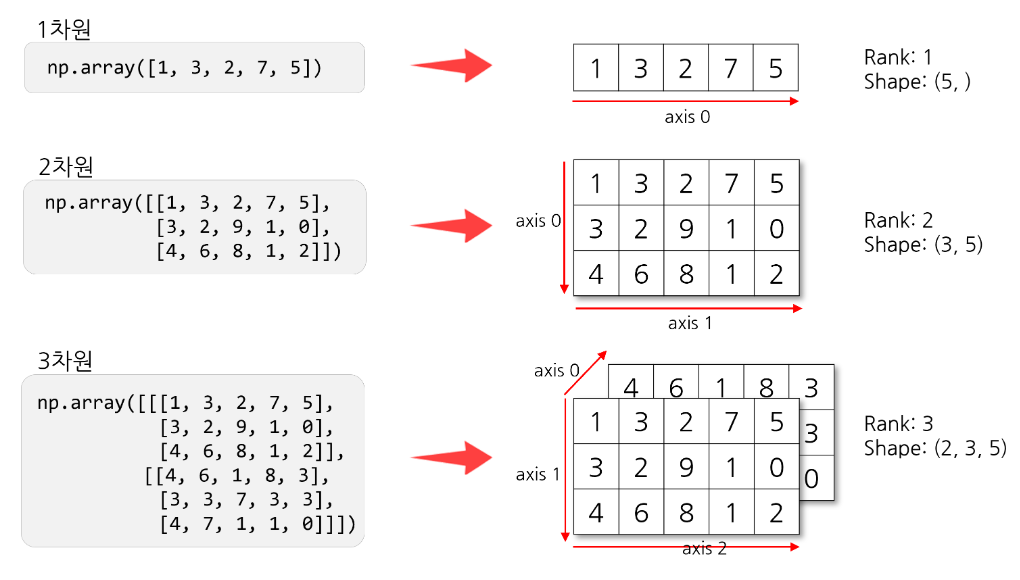
- 배열에 대한 이해 -
Axis 0의 의미데이터의 건수- 2차원 데이터 : (
1000, 10)- 10개의 값(열, 변수)으로 구성된 데이터
1000건 - 분석 대상이
1000건, 각 대상은 10개의 정보로 구성됨
- 10개의 값(열, 변수)으로 구성된 데이터
- 3차원 데이터: (
2500, 28, 28)- 28행 28열 (28 X 28) 크기의 2차원 데이터가
2500건 - 만약 흑백 이미지라면 28 X 28 이미지가
2500장
- 28행 28열 (28 X 28) 크기의 2차원 데이터가
배열 변환과 연산
기본 연산 (사칙 연산)
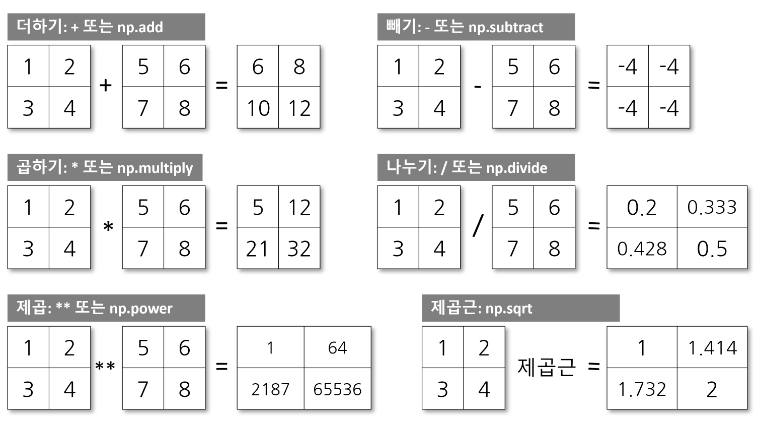
# numpy
import numpy as np
## 1. 배열 만들기
a2 = [[1.5, 2.5, 3.2],
[4.2, 5.7, 6.4]]
b2 = np.array(a2) # 배열로 변환
print(b2.ndim) # 차원 확인
print(b2.shape) # 형태(크기) 확인
print(b2.dtype) # 요소 자료형 형식 확인
b3 = b2.reshape(3, 2) # (3, 2) 형태의 2차원 배열로 Reshape
b4 = b2.reshape(6) # (6, )형태의 1차원으로 변경
b5 = b2.reshape(3, -1) # 3행을 맞추고 열은 알아서 자동으로 맞춤 (가능한 형태만 변환 가능)
## 2. 배열 인덱싱, 슬라이싱, 조건 조회
print(a[0, 1]) # 첫 번째 행, 두 번째 열 요소 조회
print(a[[0, 1]]) # print(a[[0, 1], :]) | 첫 번째, 두 번째 행 조회
print(a[:, [0, 1]]) # 첫 번째, 두 번째 열 조회
print(a[[1], [1]]) # 두 번째 행 두 번째 열의 요소 조회
print(a[0:3, 1:3]) # 첫 번째 ~ 세 번째 행, 두 번째 ~ 세 번째 열 조회(조회 결과 2차원 배열)
print(score[(score >= 90) & (score < 95)]) # 모든 요소 중에서 90 이상 95 미만인 것만 조회(조회 결과 1차원 배열)
## 3. 배열 연산
print(np.sum(a)) # 전체 집계
print(np.sum(a, axis = 0)) # 열기준 집계
print(np.sum(a, axis = 1)) # 행기준 집계
print(np.argmax(a)) # 전체 중에서 가장 큰 값의 인덱스
print(np.argmax(a, axis = 0)) # 행 방향 최대값의 인덱스
print(np.argmax(a, axis = 1)) # 열 방향 최대값의 인덱스
np.where(a > 2, a, 0)
판다스(Pandas)
- 데이터프레임 구성
- 열(변수, feature, target) → 의미:
정보 - 행(관측치, 샘플) → 의미:
분석단위
- 열(변수, feature, target) → 의미:
- 데이터프레임 조회
df.loc[ : , [열 이름1, 열 이름2,...]]=df[[열 이름1, 열 이름2,...]]- 열 부분은 생략할 수 있었지만,
행 부분을 생략할 수는 없다
- 열 부분은 생략할 수 있었지만,
- 조건을 만족하는 행의 일부 열 조회
df.loc[조건, ['열 이름1', '열 이름2',...]]형태로 조회할 열을 리스트로 지정 → 2차원, 데이터프레임 형태로 조회
- 데이터프레임 집계
dataframe.groupby( ‘집계 기준 변수’, as_index = )[‘집계 대상 변수’].집계 함수집계 기준 변수: ~~별에 해당되는 변수 혹은 리스트. 범주형 변수(예: 월 별, 지역 별등)집계 대상 변수: 집계 함수로 집계할 변수 혹은 리스트. (예: 매출액 합계)
[ ['feature1', 'feature2'] ].sum()형태와 같이 집계 대상 열을 리스트로 지정by=['feature1', 'feature2']과 같이 집계 기준 열을 여럿 설정할 수도 있다- 여러 함수로 한꺼번에 집계 .agg
df.groupby( ).agg(['함수1','함수2', ...])
# pandas
import pandas as pd
## 1. 데이터프레임 생성
dict1 = {'Name': ['Gildong', 'Sarang', 'Jiemae', 'Yeoin'],
'Level': ['Gold', 'Bronze', 'Silver', 'Gold'],
'Score': [56000, 23000, 44000, 52000]}
df = pd.DataFrame(dict1) # 열 이름 : 딕셔너리의 키, 인덱스 지정 X : 행 번호
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic_simple.csv'
data = pd.read_csv(path)
## 2. 데이터프레임 탐색
df.head() # 상위 5개 확인
data.tail(3) # 하위 3개 행 데이터
data.shape # 행 수와 열 수 확인
print(data.columns) # 열 확인
print(data.columns.values) # np array 형태
list(data) # 데이터프레임을 리스트 함수에 넣으면 열 이름이 리스트로 반환됨.
data.dtypes # 열 자료형 확인
data.info() # 열 자료형, 값 개수 확인
data.describe() # 기초통계정보
# 복합 열 정렬 : 별도로 저장하고, 인덱스 reset
temp = data.sort_values(by=['JobSatisfaction', 'MonthlyIncome'], ascending=[True, False])
temp.reset_index(drop = True)
print(data['MaritalStatus'].unique()) # MaritalStatus 열 고유값 확인
print(data['MaritalStatus'].value_counts()) # MaritalStatus 열 고유값 개수 확인
print(data['MonthlyIncome'].sum()) # MonthlyIncome 열 합계 조회(max, mean, median 등 -> groupby와 같이 사용됨)
## 3. 데이터프레임 조회
data['Attrition'] # Attrition 열 조회 : 시리즈로 조회
data[['Attrition', 'Age' ]] # Attrition, Age 열 조회 : 데이터프레임으로 조회
data.loc[(data['DistanceFromHome'] > 10) & (data['JobSatisfaction'] == 4)] # and로 여러 조건 연결
data.loc[(data['DistanceFromHome'] > 10) | (data['JobSatisfaction'] == 4)] # or 조건 : |
data.loc[data['JobSatisfaction'].isin([1,4])]# 해당 값에 속한 데이터들 나열
data.loc[data['Age'].between(25, 30)] # 범위 지정 (inclusive = 'both'(기본값), 'left', 'right', 'neither' | 등호의 유무)
data.loc[data['MonthlyIncome'] >= 10000, ['Age', 'MaritalStatus', 'TotalWorkingYears']] # 조건에 맞는 여러 열 조회
# 나이(Age)가 10대(10이상, 20 미만)인 남자 청소년의 평균 운임(Fare)
titanic.loc[(titanic['Age'].between(10, 20, inclusive = 'left')) & (titanic['Sex'].isin(['male']))]['Fare'].mean()
## 4. 데이터프레임 집계
data[['MonthlyIncome', 'TotalWorkingYears']].mean() # MonthlyIncome, TotalWorkingYears 각각의 평균
# MaritalStatus 별 Age 평균 --> 데이터프레임
data.groupby('MaritalStatus', as_index=False)[['Age']].mean() # as_index=False: 행 번호를 기반으로 인덱스 설정
# 'MaritalStatus', 'Gender'별 나머지 열들 평균 조회
data_sum = data.groupby(['MaritalStatus', 'Gender'], as_index=False)[['Age','MonthlyIncome']].mean()
# 여러 함수로 한꺼번에 집계
data_agg = data.groupby('MaritalStatus', as_index=False)[['MonthlyIncome']].agg(['min','max','mean'])
