2주차 | 데이터 처리(Data processing)
KT AIVLE SCHOOL 5기 2주차에 진행한 데이터 처리(Data processing) 강의 내용 정리 글입니다.
데이터 전처리
Raw data → 데이터 구조 만들기 → 데이터 전처리 for 모델링
- 데이터 구조 만들기
- 행, 열의 하나의 데이터셋
- 모델링을 위한 전처리
- 모델링 가능한 데이터셋
- 모든 셀은 값이 있어야
- 모든 값은 숫자
- 필요 시, 숫자의 범위 맞춰야
데이터 프레임 변경
## 데이터프레임 변경
# 열 이름 변경
tip.columns = ['total_bill', 'tip', 'sex', 'smoker', 'day', 'time', 'size']
tip.rename(columns={'total_bill_amount': 'total_bill',
'male_female': 'sex',
'smoke_yes_no': 'smoker',
'week_name': 'day',
'dinner_lunch': 'time'}, inplace=True)
# Income_LY 열 추가
data['Income_LY'] = data['M_Income'] / (1+data['PctSalHike']/100 )
# 열 삭제 (copy 후 수행하기)
data2 = data.copy()
data2.drop(['JobSat2','Diff_Income'], axis=1, inplace=True) # 열 두 개 삭제(axis=0 : 행 삭제(기본값))
# 값 변경 (copy 후 수행하기)
data2.loc[data2['Diff_Income'] < 1000, 'Diff_Income' ] = 0 # Diff_Income 의 값이 1000보다 작은 경우, 0로 변경
data2['Age'] = np.where(data2['Age'] > 40, 1, 0) # Age가 40보다 많으면 1, 아니면 0으로 바꿔 봅시다.
data['Gen'] = data['Gen'].map({'Male': 1, 'Female': 0}) # Male -> 1, Female -> 0
# 수치형 -> 범주형으로 변경 시 사용
age_group = pd.cut(data2['Age'], bins =[0, 40, 50, 100] , labels = ['young','junior','senior'])
데이터프레임 결합
concat()(1) 세로로 합치기 :
axis = 0→ 칼럼 이름 기준- ‘outer’: 모든 행과 열 합치기(기본값)
- ‘inner’: 같은 행과 열만 합치기
(2) 가로로 합치기 :
axis = 1→ 행 인덱스 기준- ‘outer’: 모든 행과 열 합치기(기본값)
- ‘inner’: 같은 행과 열만 합치기
merge(join)- 판다스에서
join은 굉장히 간단 - 자동으로
key를 잡아준다 default :
inner join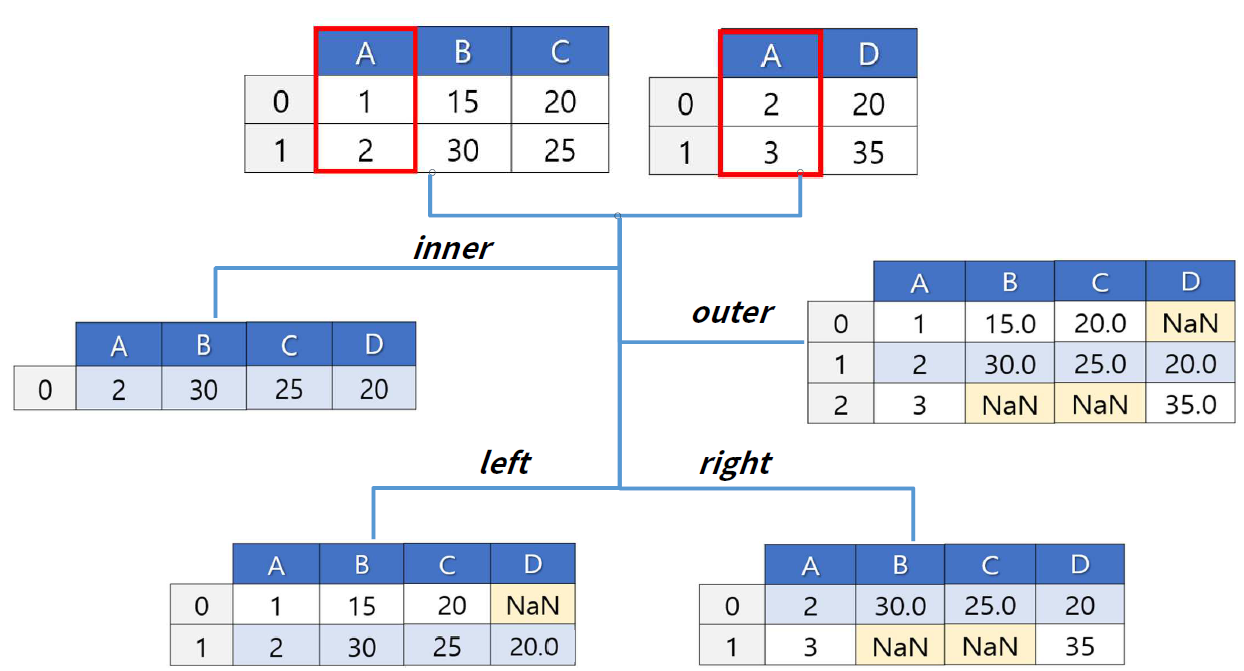
- 판다스에서
pivotpivot: 결합은 아니지만, 집계 후 데이터프레임 구조를 변형해서 조회하는데 종종 사용- 단계
groupbypivot
정리
기준 입력 방향 concat df의 구조 (인덱스, 열 이름 기준) [ ] axis = 0, 1 merge 특정 열의 값 _, _ X, 옆으로 병합 pd.concat([df1, df2], axis = 0, join = 'outer') # 집계후 agg 사용하여 열 이름 변경 s1 = sales1.groupby(['Date'], as_index = False)['Qty'].agg({'Store1_Qty':'sum'})
시계열 데이터 처리
시계열 데이터
- 행과 행에 시간의 순서가 있고, 행과 행의 시간 간격이 동일
- Time Series Data ⊂ Sequential Data
날짜 요소 추출
(1) 날짜 타입으로 변환
pd.to_datetime(날짜데이터, format = '입력되는 날짜 형식')- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.to_datetime.html
format = ''pd.to_datetime(date, format = '%d/%m/%Y'): 입력되는 날짜가 이런 형태야~~ 라고 알려주는 옵션- https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior
(2) 날짜 요소 추출
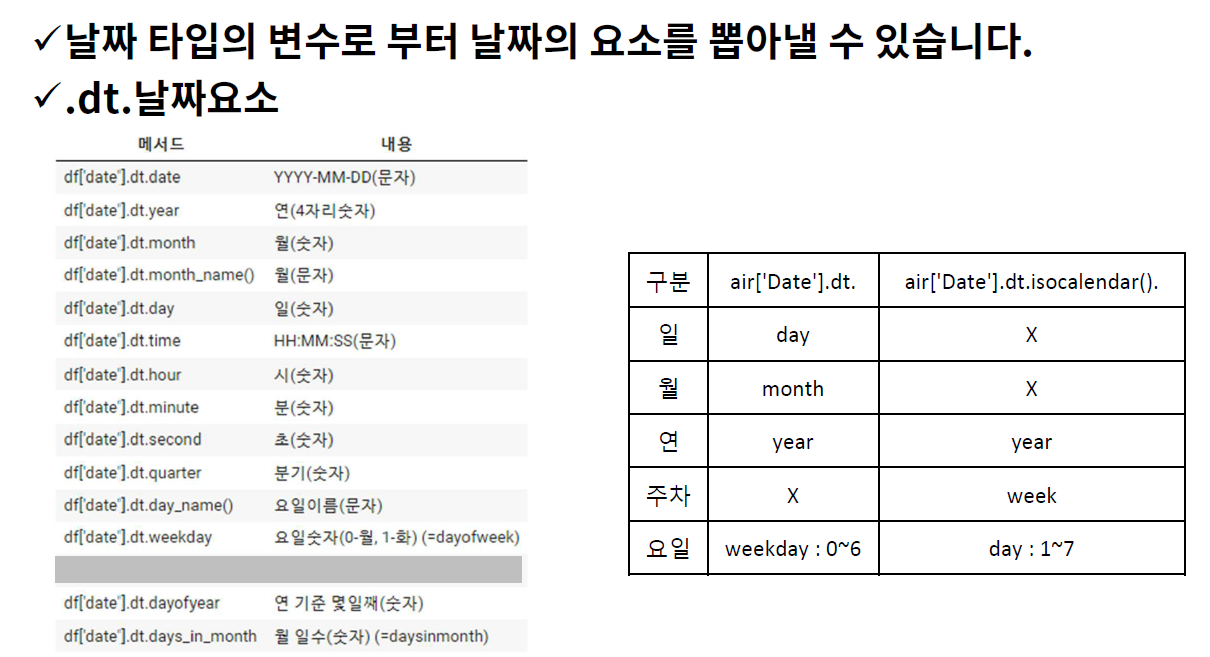
시간에 따른 흐름 추가하기
(1)
shift- 시계열 데이터에서 시간의 흐름 전후로 정보를 이동시킬 때 사용
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.shift.html
# 전날 매출액 열을 추가 temp['Amt_lag'] = temp['Amt'].shift() #default = 1 # 전전날 매출액 열을 추가 temp['Amt_lag2'] = temp['Amt'].shift(2) # 2행 shift # 다음날 매출액 열을 추가 temp['Amt_lag_1'] = temp['Amt'].shift(-1) temp.head()
(2)
rolling + 집계함수- 시간의 흐름에 따라 일정 기간 동안 평균을 이동하면서 구하기
.rolling: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.rolling.htmlrolling(n):n기본값은 1min_periods: 최소 데이터수
# 7일 이동평균 매출액을 구하기 temp['Amt_MA7_1'] = temp['Amt'].rolling(7).mean() temp['Amt_MA7_2'] = temp['Amt'].rolling(7, min_periods = 1).mean() temp.head(10)
(3)
diff- 특정 시점 데이터, 이전시점 데이터와의 차이 구하기
.diff: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.diff.html# 1일, 2일 이전 데이터와의 차이 구하기 temp['Amt_D1'] = temp['Amt'].diff() temp['Amt_D2'] = temp['Amt'].diff(2) temp.head(10)
연습 문제
[문1] data의 Grocery가 매출이 가장 높습니다. 이에 대해서 다음의 열을 추가해 봅시다.
- 전날 매출액
- 7일 전(전주 동 요일) 매출액
- 3일 이동평균 매출액
- 전날대비 매출액 증감여부 (증가 1, 감소 -1, 동일 0)
temp = data.loc[:, ['Date', 'Grocery']] # 전날 매출액 temp['Grocery_shift'] = temp['Grocery'].shift() # 7일 전(전주 동 요일) 매출액 temp['Grocery_shift_week'] = temp['Grocery'].shift(7) # 3일 이동평균 매출액 temp['Grocery_rolling_mean_3'] = temp['Grocery'].rolling(3).mean() # 전날대비 매출액 증감여부 (증가 1, 감소 -1, 동일 0) temp['diff_check'] = np.where(temp['Grocery'].diff() > 0, 1, np.where(temp['Grocery'].diff() < 0, -1, 0)) temp.head(10)
데이터 분석 방법
CRISP-DM
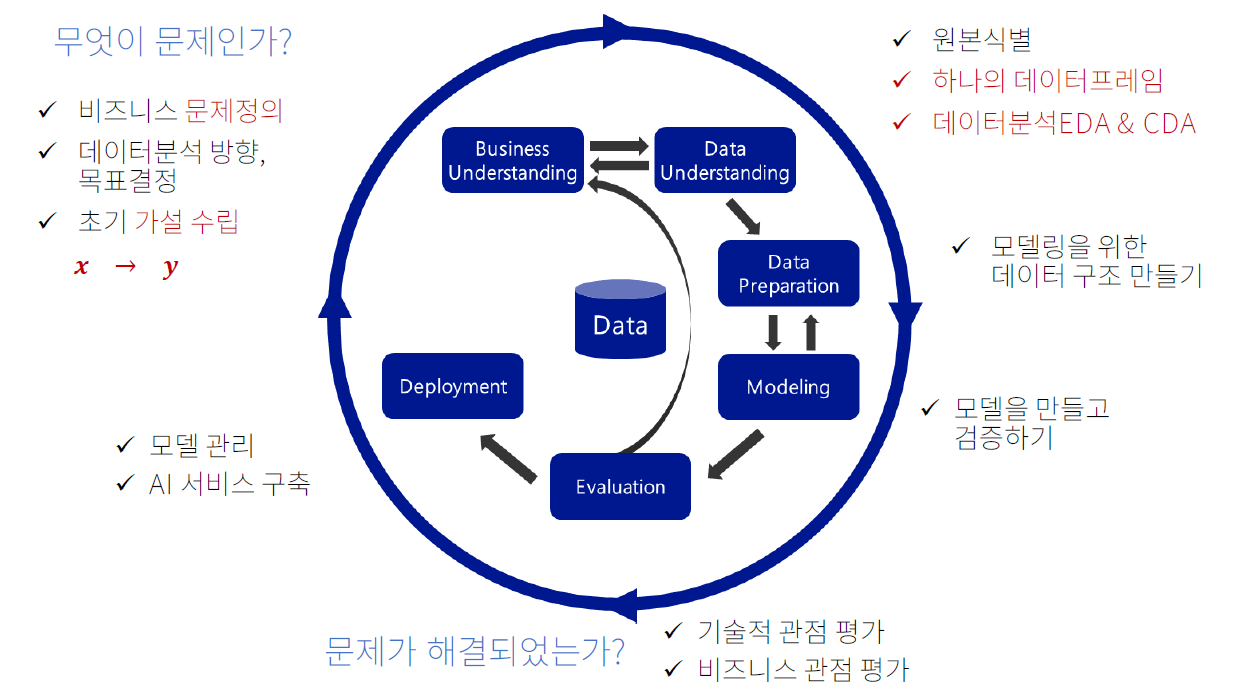
- Business Understanding(비즈니스 이해)
- 문제 정의
- 분석 방향, 목표
- 가설: x → y (정보: 범주형, 수치형)
- Data Understanding(데이터 이해)
- 데이터 원본(소스) 식별 및 취득
- (초기)가설에서 도출된 데이터의 원본을 확인
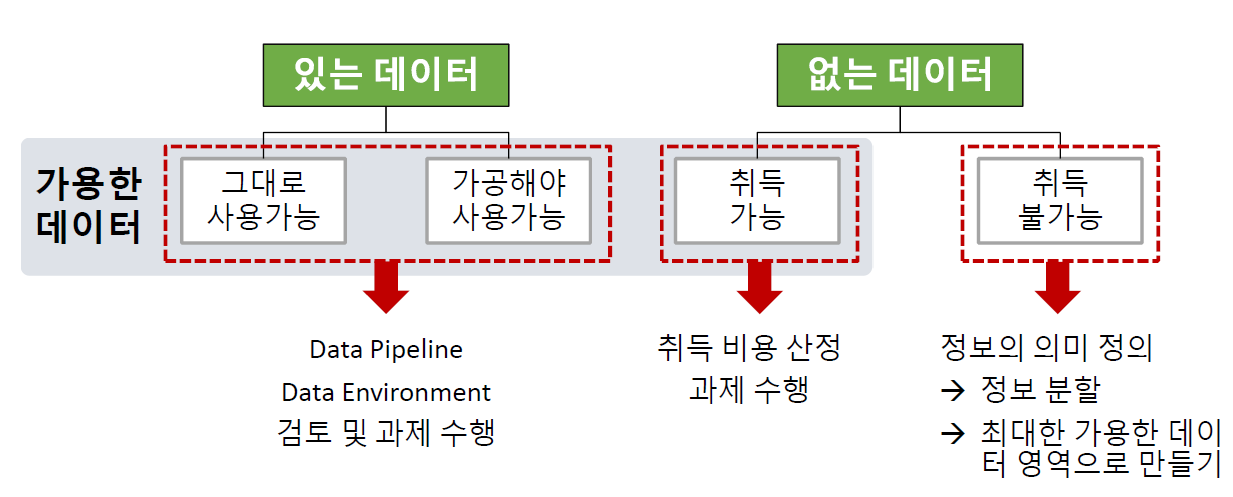
데이터 탐색: EDA, CDA
수치형 범주형 기초통계량 min, max, mean, 사분위수 범주별 빈도수, 비율 그래프 (시각화) hist, kdeplot, boxplot bar plot EDA(Exploratory Data Analysis): 개별 데이터의 분포, 가설이 맞는지 파악, NA, 이상치 파악 → 탐색적 데이터 분석 (그래프, 통계량)CDA(Confirmatory Data Analysis): 탐색으로 파악하기 애매한 정보는 통계적 분석 도구(가설 검정) 사용 → 확증적 데이터 분석 (가설검정, 실험)- 정리된 2차원 구조의 데이터셋 분석 방법
- 초기 가설 + 준비된 데이터셋
- EDA + CDA
- 가설 확인, 전처리 대상 정리 (data pipeline), 데이터와 비즈니스에 대해 더 잘 이해
- EDA, CDA 진행 순서
- 단변량 분석: 개별 변수의 분포
- ex) 타이타닉 탑승객의 나이 분석
- 이변량 분석1: feature와 target 간의 관계 (가설을 확인하는 단계)
- ex) 객실등급 → 생본여부 (객실등급에 따라 생존여부에 차이가 있나?)
- 이변량 분석2: feature들 간의 관계
- 단변량 분석: 개별 변수의 분포
- 데이터 원본(소스) 식별 및 취득
- Data Preparation(데이터 준비)
- 개요: 모든 셀에 값이 있고, 모든 값은 숫자이고, 값의 범위를 일치시켜야 한다
- 수행 내용: 결측치 조치, 가변수화, 스케일링, 데이터 분할
- Modeling(모델링)
- 모델링 (학습, Learning, Training)
- 데이터로부터 패턴을 찾는 과정
- 오차를 최소화 하는 패턴
- 결과물: 모델(수학식으로 표현됨)
- 모델링에 필요한 두 가지
- 학습 데이터
- 알고리즘
- 모델링 (학습, Learning, Training)
- Evaluation(평가)
- Deployment(배포)
파일럿 프로젝트: 본 게임 전에 해보는 프로젝트
위의 그림과 같은 과정을 프로젝트 진행 시 사이클을 많이 돌아야 한다
- 한기영 강사님의 프로젝트 심사 질문
- 프로젝트로 실제 현장의 문제가 해결 되었는가?
- 다시 초기 단계로 돌아간다면 어떤 부분을 보완 할건가요?
- Business Understanding(비즈니스 이해)
시각화 라이브러리
수 많은 데이터를 한 눈에 파악하는 두 가지 방법 → 그래프(시각화), 통계량(수치화)
데이터 시각화의 목적: 비즈니스의 인사이트를 파악하는 것
기초
x축, y축 이름, 타이틀 붙이기
plt.plot(data['Date'], data['Ozone']) plt.xticks(rotation = 30) # x축 값 꾸미기 : 방향을 30도 틀어서 plt.xlabel('Date') # x축 이름 지정 plt.ylabel('Ozone') # y축 이름 지정 plt.title('Daily Airquality') # 타이틀 plt.show() # 위에 있는 것들을 한꺼번에 그려줘- 라인 스타일 조정
color=- ‘red’,’green’,’blue’ …
- 혹은 ‘r’, ‘g’, ‘b’, …
- https://matplotlib.org/stable/gallery/color/named_colors.html
linestyle=- ‘solid’, ‘dashed’, ‘dashdot’, ‘dotted’
- 혹은 ’-‘ , ‘–’ , ‘-.’ , ‘:’
- marker=
marker description ”.” point ”,” pixel “o” circle “v” triangle_down ”^” triangle_up ”<” triangle_left ”>” triangle_right 여러 그래프 겹쳐서 그리기
# 첫번째 그래프 plt.plot(data['Date'], data['Ozone'], color='green', linestyle='dotted', marker='o') # 두번째 그래프 plt.plot(data['Date'], data['Temp'], color='r', linestyle='-', marker='s') plt.xlabel('Date') plt.ylabel('Ozone') plt.title('Daily Airquality') plt.xticks(rotation=45) # 위 그래프와 설정 한꺼번에 보여주기 plt.show()범례, 그리드 추가
plt.plot(data['Date'], data['Ozone'], label = 'Ozone') # label = : 범례추가를 위한 레이블값 plt.plot(data['Date'], data['Temp'], label = 'Temp') plt.legend(loc = 'upper right') # 레이블 표시하기. loc = : 위치 plt.grid() plt.show()
추가 기능
(1) 데이터프레임.plot()
(2) 축 범위 조정하기
plt.plot(data['Ozone'])
plt.ylim(0, 100)
plt.xlim(0,10)
plt.grid()
plt.show()
(3) 그래프 크기 조정
plt.figure(figsize = (4, 3))- default size는 6.4, 4.4
(4) 수평선 수직선 추가
plt.plot(data['Ozone'])
plt.axhline(40, color = 'grey', linestyle = '--')
plt.axvline(10, color = 'red', linestyle = '--')
plt.show()
(5) 그래프에 텍스트 추가
plt.plot(data['Ozone'])
plt.axhline(40, color = 'grey', linestyle = '--')
plt.axvline(10, color = 'red', linestyle = '--')
plt.text(5, 41, '40')
plt.text(10.1, 20, '10')
plt.show()
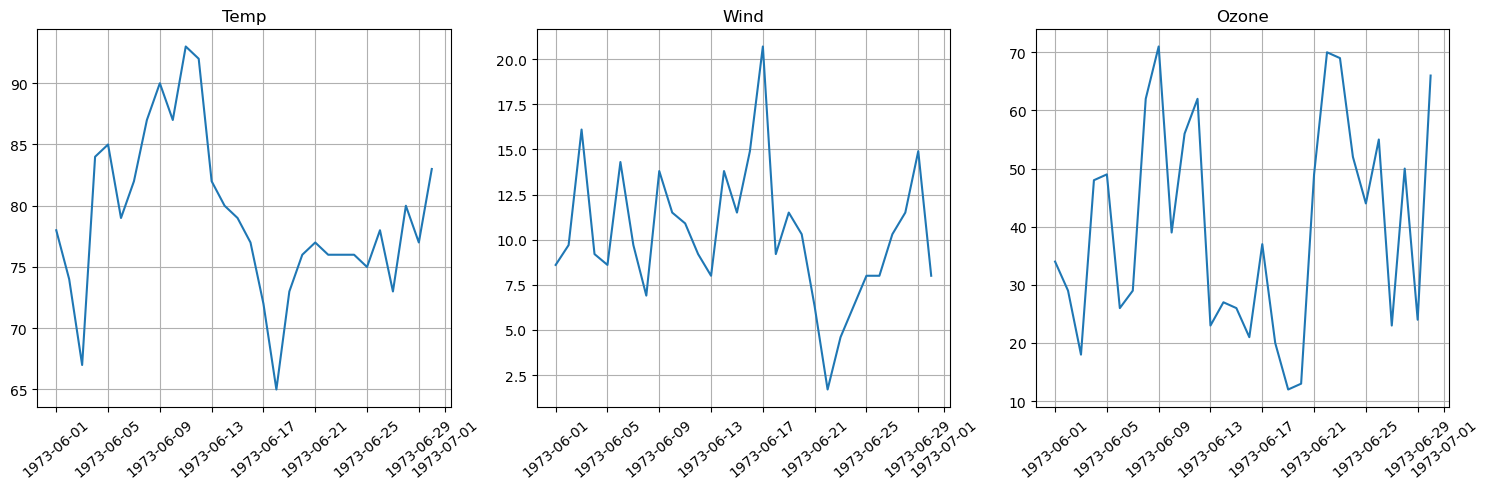
(6) 그래프 여러개 그리기
plt.figure(figsize = (15,5))
plt.subplot(1,3,1)
plt.plot('Date', 'Temp', data = data)
plt.title('Temp')
plt.xticks(rotation = 40)
plt.grid()
plt.subplot(1,3,2)
plt.plot('Date', 'Wind', data = data)
plt.title('Wind')
plt.xticks(rotation = 40)
plt.grid()
plt.subplot(1,3,3)
plt.plot('Date', 'Ozone', data = data)
plt.title('Ozone')
plt.xticks(rotation = 40)
plt.grid()
plt.tight_layout() # 그래프간 간격을 적절히 맞추기
plt.show()
단변량 분석 - 숫자형
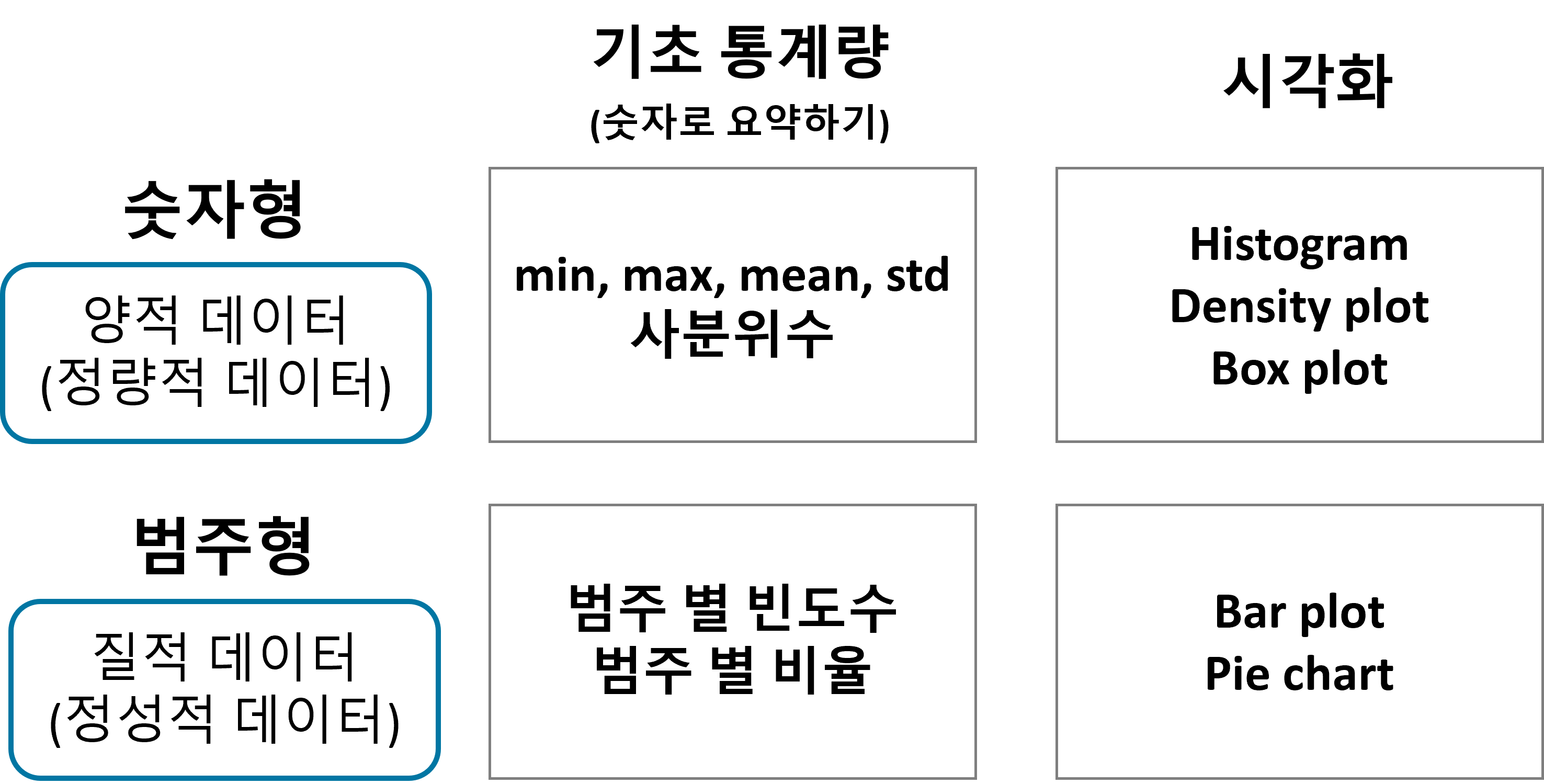
숫자형 변수 정리하는 방법
- 숫자로 요약하기: 정보의 대푯값 → 기초 통계량 (
mean, median, mode)- 평균은 정규분포와 같은 분포를 나타낼 때 좋다 → 극단적인 경우에 좋지 않을 수 있다
- 사분위수: 데이터를 오름차순으로 정렬 후, 사등분 → 대략적인 분포를 알 수 있게 해준다
df.describe(): 기초 통계량 확인- Box plot
- 구간을 나누고 빈도수(
frequency) 계산 → 도수분포표- histogram, Density plot(KDE)
시각화
1) 히스토그램
- 구간을 나누고 그 구간에 따른 빈도수를 나타낸 그래프
- 구간의 개수에 따라서 파악할 수 있는 내용이 달라짐 →
bins를 적절히 조절 - 단순 해석을 넘어서 비즈니스적인 관점에서의 해석이 중요하다
Seaborn패키지가 조금 더 유용
- 구간의 개수에 따라서 파악할 수 있는 내용이 달라짐 →
- 그래프 읽기
- 희박하고 밀집된 정도에 따르는 비즈니스 의미 파악
2) 밀도 함수 그래프(kde plot)
- 히스토그램의 단점
- 구간(bin)의 너비를 어떻게 잡는 지에 따라 전혀 다른 모양이 될 수 있음
- 밀도 함수 그래프
- 막대의 너비를 가정하지 않고 모든 점에서 데이터의 밀도를 추정하는 커널 밀도 추정(Kernel Density Estimation)방식을 사용하여 이러한 단점을 해결
- 밀도함수 그래프 아래 면적은 1
- 분포 확인 용으로 사용
- 히스토그램에서 KDE plot 함께 그리기
3) boxplot
plt.boxplot()- 값에 NaN이 있으면 그래프가 그려지지 않는다
- 방향은
vert옵션 →True(종, 기본 값),False(횡)
sns.boxplot()seaborn패키지 함수들은 NaN을 알아서 빼줌- 방향은
x, y로 바꿈
- 두 부분: 박스 & 수염
- 박스: 4분위수
- 수염
- IQR: 3사분위수 - 1사분위수
- Actual Whisker Length: 1.5 * IQR 범위 이내의 최소, 최대값으로 결정
- Potential Whisker Length: 1.5 * IQR 범위, 잠재적 수염의 길이 범위
- 값의 분포도 그려볼 수 있다
- 이상치 확인도 가능
- 최근에는 이상치의 영향을 덜 받는 모델들이 많이 나옴(이상치 별로 신경 안씀)
- 이상탐지 영역에서는 중요
- IQR: 3사분위수 - 1사분위수
- 히스토그램, KDE, Box plot을 한번에 시각화해서 분포확인 많이 한다
4) 시계열 데이터 시각화
- 시계열 데이터는 보통 시간 축(x축)에 맞게 값들을 라인 차트로 표현
수치형 단변량 분석 함수
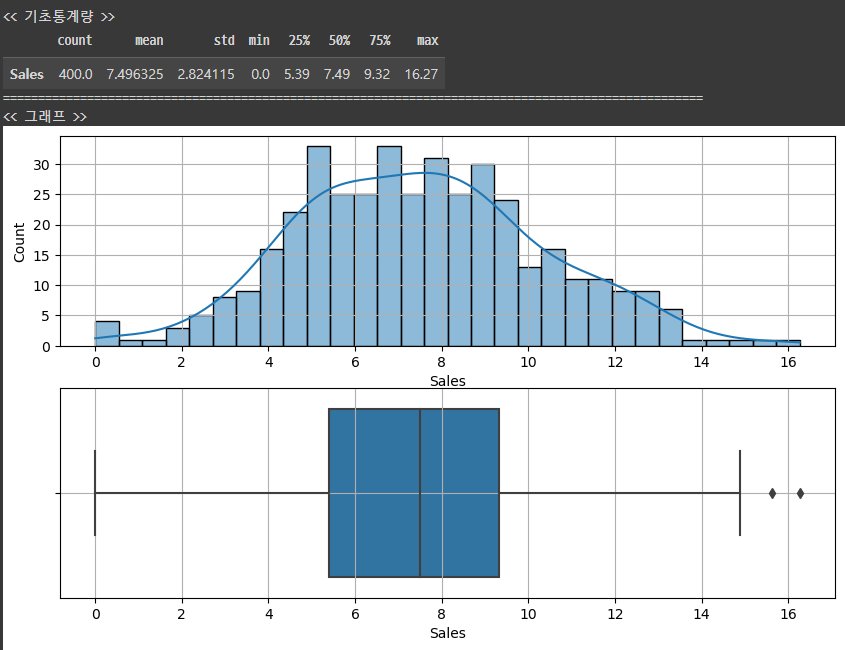
def eda_1_num(data, var, bins = 30):
# 기초통계량
print('<< 기초통계량 >>')
display(data[[var]].describe().T)
print('=' * 100)
# 시각화
print('<< 그래프 >>')
plt.figure(figsize = (10,6))
plt.subplot(2,1,1)
sns.histplot(data[var], bins = bins, kde = True)
plt.grid()
plt.subplot(2,1,2)
sns.boxplot(x = data[var])
plt.grid()
plt.show()
단변량 분석 - 범주형
수치화 : 기초통계량
범주형 변수는 범주별 빈도수와 비율을 확인
1) 범주별 빈도수
.value_counts(): 범주의 개수와 상관 없이 범주 별 개수를 count
2) 범주별 비율
.value_counts(normalize = True)
시각화
1) bar chart
seaborn의countplotplt.bar()를 이용하려면 먼저 집계한 후 결과를 가지고 그래프를 그려야 한다countplot은 집계 +bar plot을 한꺼번에 해결!
범주형 단변량 분석 함수
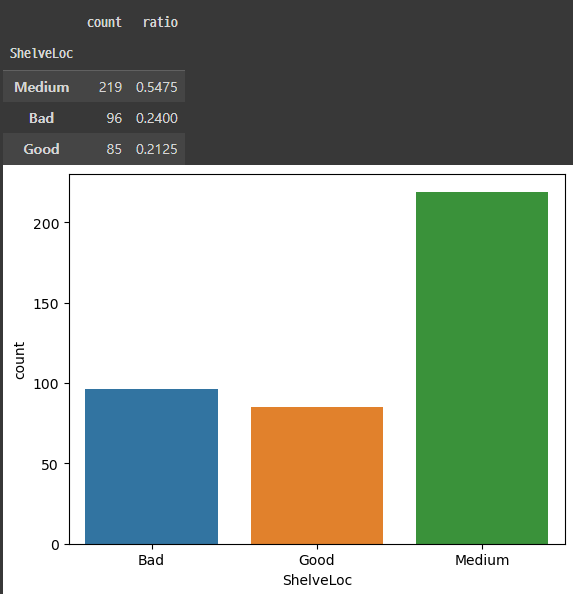
def eda_1_cat(data, var) :
# 기초통계량
t1 = data[var].value_counts()
t2 = data[var].value_counts(normalize = True)
t3 = pd.concat([t1, t2], axis = 1)
t3.columns = ['count','ratio']
display(t3)
# 그래프
sns.countplot(x = var, data = data)
plt.show()