6주차 | 딥러닝(Deep learning)(2)
KT AIVLE SCHOOL 5기 6주차에 진행한 딥러닝(Deep learning) 강의 내용 정리 글입니다.
성능관리
딥러닝 모델 성능 높이기
- 데이터
- 입력 데이터 정제, 적절한 전처리
- 데이터 늘리기:
- 열(적절한 feature 추가) → 성능 향상 (Bias 줄이기)
- 행(데이터 건수 늘리기) → 편차 줄이기(Variance 줄이기)
- 모델 구조
- Hidden Layer, 노드 수 늘리기 : 성능이 증가할 때 까지
- 반복문 / keras-tuner
- 학습
- epochs : 10 ~ 50에서 시작
- Model check point / Early Stopping 으로 최적 모델 저장 가능
- learning rate : 0.1 ~ 0.001 사이에서 시작
- epochs : 10 ~ 50에서 시작
과적합 문제
- 모델링 목적 : 모집단 전체에서 두루 잘 맞추는 (적당한) 모델 만들기
- 과적합 : 학습 데이터에서만 높은 성능, 다른 데이터에서는 낮은 성능
과적합 방지하기
- 적절한 모델 생성
- 모델의 복잡도 : 학습용 데이터의 패턴을 반영하는 정도
- 적절한 복잡도 지점 찾기 : 복잡도를 조금씩 조절해 가면서 Train error와 Validation error를 측정하고 비교
- 딥러닝에서의 조절
- Epoch와 learning_rate
- 모델 구조 조정 : hidden layer, node 수
- Early Stopping
- Regularization(규제) : L1, L2
- Dropout
- Early Stopping
- epoch가 많으면 과적합 될 수 있음
- 항상 발생하지는 않지만 반복할수록 오차 감소 → 증가할 수 도 있음
- 옵션
monitor: 기본값 (val_loss)min_delta: 오차의 최소값에서 줄어드는 변화량이 몇 이상인지 지정 (기본 0)patience: 오차가 줄지 않는 상황을 몇번 기다릴지 지정 (기본 0)
- epoch가 많으면 과적합 될 수 있음
- 가중치 규제 (Regularization)
- 오차 함수에 페널티 추가 포함 (파라미터 정리)
- L1 규제 : Lasso
- 오차 함수 = 오차 + \(\lambda \sum \vert w \vert\)
- \(\lambda\) : 규제 강도
- 가중치(파라미터) 절대값의 합을 최소화 → 가중치가 작은 값들은 0으로 만드는 경향
- 오차 함수 = 오차 + \(\lambda \sum \vert w \vert\)
- L2 규제 : Ridge
- 오차 함수 = 오차 + \(\lambda \sum w^2\)
- 가중치 제곱의 합을 최소화
- 규제 강도에 따라 가중치 영향력을 제어
- 강도가 크면, 큰 가중치가 좀 더 줄어드는 효과 → 작은 가중치는 0에 수렴
- L1, L2 규제의 강도 : 일반적인 값의 범위
- L1 : 0.0001 ~ 0.1
- L2 : 0.001 ~ 0.5
- 강도가 높을수록 → 일반화된 모델(단순한 모델)
- Hidden Layer에서 지정
- 모든 Hidden Layer에서 지정 or 노드의 수가 많은 층에서만 지정 → 상황에 맞게 사용
- Dropout
- 훈련 과정에서 신경망의 일부 뉴런을 임의로 비활성화 시킴 → 모델 강제로 일반화
- 적용 절차
- 훈련 배치에서 랜덤하게 선택된 일부 뉴런을 제거
- 제거된 뉴런은 해당 배치에 대한 순전파 및 역전파 과정에서 비활성화
- 이를 통해 뉴런들 간의 복잡한 의존성을 줄여 줌
- 매 epochs 마다 다른 부분 집합의 뉴런을 비활성화 ➔ 앙상블 효과
- Hidden Layer 다음에 Dropout Layer 추가
- Dropout Rate
- 0.4 : hidden layer의 노드 중 40%를 임의로 제외시킴.
- 보통 0.2 ~ 0.5 사이의 범위 지정
- 조절하면서 찾아야 하는 하이퍼파라미터!
- Feature가 적을 경우 rate를 낮추고, 많을 경우는 rate를 높이는 시도
모델 저장하기
- h5 파일로 저장
- 모델 로딩: load_model 함수로 모델 로딩
- 각 epoch 마다 모델 저장 가능
실습
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.backend import clear_session
from tensorflow.keras.optimizers import Adam
from keras.datasets import mnist
from keras.callbacks import EarlyStopping
from keras.regularizers import l1, l2
from keras.layers import Dropout
from keras.models import load_model
from keras.callbacks import ModelCheckpoint
# 1. Early Stopping
# 모델 선언
clear_session()
model2 = Sequential( [Dense(128, input_shape = (nfeatures,), activation= 'relu'),
Dense(64, activation= 'relu'),
Dense(32, activation= 'relu'),
Dense(1, activation= 'sigmoid')] )
model2.compile(optimizer= Adam(learning_rate = 0.001), loss='binary_crossentropy')
# EarlyStopping 설정 ------------
min_de = 0.005
pat = 5
es = EarlyStopping(monitor = 'val_loss', min_delta = min_de, patience = pat)
# --------------------------------
# 학습
hist = model2.fit(x_train, y_train, epochs = 100, validation_split=0.2,
callbacks = [es]).history
dl_history_plot(hist)
# 2.가중치 규제(Regularization)
model4 = Sequential( [Dense(128, input_shape = (nfeatures,), activation= 'relu',
kernel_regularizer = l1(0.01)),
Dense(64, activation= 'relu',
kernel_regularizer = l1(0.01)),
Dense(32, activation= 'relu',
kernel_regularizer = l1(0.01)),
Dense(1, activation= 'sigmoid')] )
model4.compile(optimizer= Adam(learning_rate = 0.001), loss='binary_crossentropy')
hist = model4.fit(x_train, y_train, epochs = 100, validation_split=0.2, verbose = 0).history
dl_history_plot(hist)
# 3. Dropout
model3 = Sequential( [Dense(128, input_shape = (nfeatures,), activation= 'relu'),
Dropout(0.4),
Dense(64, activation= 'relu'),
Dropout(0.4),
Dense(32, activation= 'relu'),
Dropout(0.4),
Dense(1, activation= 'sigmoid')] )
model3.compile(optimizer= Adam(learning_rate = 0.001), loss='binary_crossentropy')
hist = model3.fit(x_train, y_train, epochs = 50, validation_split=0.2, verbose = 0).history
dl_history_plot(hist)
# 4. 모델 저장
model1.save('hanky.h5')
model2 = load_model('hanky.h5') # 불러온 모델 바로 사용 가능
## 중간 체크 포인트에 모델 저장
nfeatures = x_train.shape[1]
model1 = Sequential( [Dense(64, input_shape = (nfeatures,), activation= 'relu'),
Dense(32, activation= 'relu'),
Dense(16, activation= 'relu'),
Dense(1, activation= 'sigmoid')] )
model1.compile(optimizer= Adam(learning_rate = 0.0001), loss='binary_crossentropy')
cp_path = '{epoch:03d}.h5'
mcp = ModelCheckpoint(cp_path, monitor='val_loss', verbose = 1, save_best_only=True)
hist = model1.fit(x_train, y_train, epochs = 50, validation_split=.2, callbacks=[mcp]).history
dl_history_plot(hist)
#체크포인트 저장
# 아래 코드에서 ModelCheckpoint 콜백은 검증 데이터의 정확도(val_accuracy)를 기준으로 모델 저장
# 모델의 성능이 이전에 저장된 모델보다 향상될 때만 저장되도록 save_best_only=True로 설정
# 또한, verbose=1로 설정하면 모델이 저장될 때마다 콘솔에 메시지가 표시됨.
참고
- 튜닝 시 적절한 지점 찾기 : elbow method => elbow 지점을 찾고 그 근방에서 답을 찾아라
Functional API
Sequential vs Functional
- Sequential
- 구성
- 순차적으로 쌓아가며 모델 생성
- Input → Output Layer 순차적 연결
- 코드
- 리스트로 Layer 입력
- 구성
- Functional
- 구성
- 모델을 좀 더 복잡하게 구성
- 모델을 분리해서 사용 가능
- 다중 입력, 다중 출력 가능
- 코드
- Input 함수
- Layer : 앞 레이어 연결 지정
- Model 함수로 시작과 끝 연결해서 선언
- 구성
다중 입력 모델
- 다양한 종류의 입력
- 각 입력에 맞는 특징 도출(feature representation) 가능
실습
from keras.models import Sequential, Model
from keras.layers import Input, Dense, concatenate
from keras.backend import clear_session
from tensorflow.keras.optimizers import Adam
# 1. Sequential
clear_session()
model = Sequential([
Dense(18 ,input_shape = (nfeatures, ),
activation = 'relu' ),
Dense(4, activation='relu') ,
Dense(1) ])
model.summary()
# 2. Functional
clear_session()
il = Input(shape=(nfeatures, ))
hl1 = Dense(18, activation='relu')(il)
hl2 = Dense(4, activation='relu')(hl1)
ol = Dense(1)(hl2)
model = Model(inputs = il, outputs = ol)
model.summary()
# 3. 다중 입력 모델링
nfeatures1 = x_train1.shape[1]
nfeatures2 = x_train2.shape[1]
# 모델 구성
input_1 = Input(shape=(nfeatures1,), name='input_1')
input_2 = Input(shape=(nfeatures2,), name='input_2')
# 첫 번째 입력을 위한 레이어
hl1_1 = Dense(10, activation='relu')(input_1)
# 두 번째 입력을 위한 레이어
hl1_2 = Dense(20, activation='relu')(input_2)
# 두 히든레이어 결합
cbl = concatenate([hl1_1, hl1_2])
# 추가 히든레이어
hl2 = Dense(8, activation='relu')(cbl)
# 출력 레이어
output = Dense(1)(hl2)
# 모델 선언
model = Model(inputs = [input_1, input_2], outputs = output)
model.summary()
# 4. keras_tuner 성능 최적화
import keras_tuner as kt
def build_model(hp):
model = Sequential([ Dense(units=hp.Choice('node1', [8, 16, 32, 64, 128, 256]),
input_shape = (x_train.shape[1],), activation='relu'),
Dense(1)])
model.compile(loss='mean_absolute_error', optimizer=Adam(learning_rate = hp.Choice('learning_rate', [0.0001, 0.001, 0.01])))
return model
%%time
tuner = kt.RandomSearch(build_model, objective='val_loss', max_trials = 10, project_name='dnn_tune_2')
tuner.search(x_train, y_train, epochs = 100, validation_split = .2, verbose=0)
best_model = tuner.get_best_models(num_models=1)[0]
tuner.results_summary()
# 튜닝 모델을 이용하여 예측하고 평가하기
pred2_1 = best_model.predict(x_test, verbose = 0)
print('MAE :', mean_absolute_error(y_test, pred2_1))
plt.scatter(y_test, pred2_1)
plt.plot(y_test, y_test, color = 'gray', linewidth = .5)
plt.grid()
plt.show()
시계열 모델링
시계열 데이터
- Sequential Data ⊃ Time Series
- 순서가 있다
- Sequential + 시간의 등간격
- 시계열 데이터 분석
- 시간의 흐름에 따른 패턴을 분석
- 흐름을 어떻게 정리하는 지에 따라서 모델링 방식이 달라짐
시계열 모델링 개요
- 통계적 시계열 모델링
- y의 이전 시점 데이터들로 부터 흐름의 패턴을 추출하여 예측
- 패턴 : trend, seasonality
- x 변수 사용하지 않음
- 패턴이 충분히 도출된 모델의 잔차는 Stationary
- y의 이전 시점 데이터들로 부터 흐름의 패턴을 추출하여 예측
- ML 기반 시계열 모델링
- 특정 시점 데이터들(1차원)과 예측 대상 시점(\(y_{t+1}\)) 과의 관계로 부터 패턴을 추출하여 예측
- 시간의 흐름을 x변수로 도출하는 것이 중요
- 특정 시점 데이터들(1차원)과 예측 대상 시점(\(y_{t+1}\)) 과의 관계로 부터 패턴을 추출하여 예측
- DL 기반 시계열 모델링 (RNN)
- 시간 흐름 구간(timesteps) 데이터들(2차원)과 예측 대상 시점(\(y_{t+1}\)) 과의 관계로 부터 패턴 추출
- 어느 정도 구간(timesteps)을 하나의 단위로 정할지 결정
- 분석 단위를 2차원으로 만드는 전처리 필요 → 데이터셋은 3차원
- 시간 흐름 구간(timesteps) 데이터들(2차원)과 예측 대상 시점(\(y_{t+1}\)) 과의 관계로 부터 패턴 추출
- 시계열 모델링 절차
- y 시각화, 정상성 검토(통계적 모델, 화이트 노이즈: 잔차에 패턴이 없는 상태)
- 모델 생성
- Train_err(잔차) 분석 → 2번으로 올라가기 반복
- 검증(예측)
- 검증(평가) → 2번으로 올라가기 반복
- 시계열 모델 평가
- 기술적 평가
- 잔차
- ACF, PACF
- 검정 : 정상성 검정, 정규성 검정, …
- ML Metric
- AIC
- MAE, MAPE, R2
- 잔차
- 비즈니스 평가
- 수요량 예측
- 재고 회전율
- 평균 재고 비용
- 수요량 예측
- 기술적 평가
- 잔차 분석
- 잔차(Residual) = 실제 데이터 - 예측값
- 시계열 모델 \(y = f(x) +\epsilon\)
- 잔차 \(\epsilon\) 는 White Noise에 가까워야 함
- 가깝지 않다면 y의 패턴을 제대로 반영 못함 → 더 할일 남음
- 잔차 \(\epsilon\) 는 White Noise에 가까워야 함
- 잔차 분석
- 시각화: ACF, PACF
- 검정
- 정상성 검정(ADF Test, KPSS Test)
- 정규성 검정(Shapiro-wilk Test)
- 자기상관 검정(Ljung-Box Test)
- 등분산성 검정(G-Q Test)
딥러닝 기반 시계열 모델링(RNN)
RNN
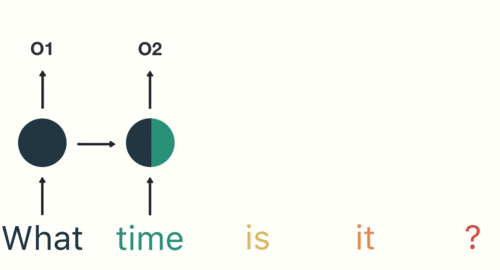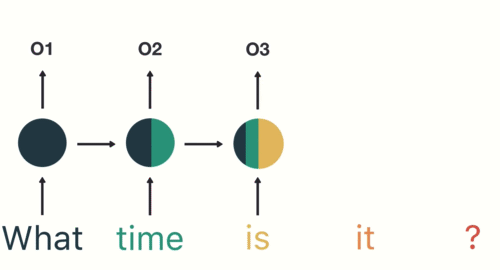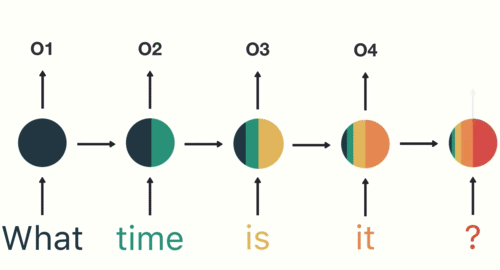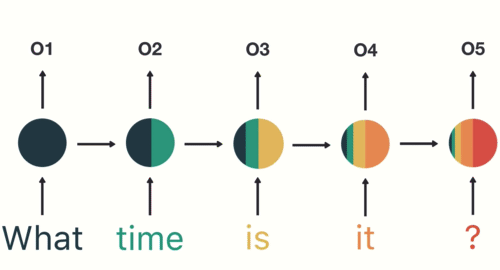
RNN: 시계열 데이터 모델링
- 최근 4일간의 데이터를 기반으로 다음날 주가 예측
- 최근 4일간의 주가, 거래량, 환율, 유가의 흐름을 학습해서 다음날 주가를 예측하는 모델
- 𝑥0, 𝑥1, 𝑥2, 𝑥3 : input
- ℎ0, ℎ1, ℎ2, ℎ3 : hidden state (중간 결과물)
- 과거의 정보를 현재에 반영해 학습하도록 설계
- 주의 사항: 사전 확인 오류를 범하지 말아야 한다
- 데이터 전처리
- 데이터 분할 1: x, y
- 스케일링
- X 스케일링 필수
- y값이 크면 최적화를 위해 스케일링 필요 → 단, 모델 평가 시 원래 값으로 복원
- 3차원 데이터셋 만들기
- 2차원 데이터셋(x) → timesteps 단위로 잘라서 (한칸씩 밀면서, sliding window)
- 데이터 분할2 : train, val
- SimpleRNN
- 노드 수 1개 ➔ 레이어의 출력 형태 : timesteps * 노드 수
- return_sequences : 출력 데이터를 다음 레이어에 전달할 크기 결정
- True : 출력 크기 그대로 전달 ➔ timesteps * node수
False : 가장 마지막(최근) hidden state 값만 전달 ➔ 1 * node 수
- 마지막 RNN Layer를 제외한 모든 RNN Layer : True
- 마지막 RNN Layer : False와 True 모두 사용 가능
- 단, True를 사용하려면 Flatten으로 펼친 후 Dense Layer 로 연결
- Flatten: 중간 과정의 hidden state 값들을 2차원에서 1차원으로 펼치기
- 단, True를 사용하려면 Flatten으로 펼친 후 Dense Layer 로 연결
- RNN의 활성화 함수: tanh(hyperbolic tangent)
- 하이퍼 볼릭 탄젠트 함수
- gradient 소실 문제 완화
- gradient 소실 문제: 역전파 시에 gradient가 작아져 학습이 어려워지는 현상
- 시그모이드에 비해 gradient를 좀 더 크게 유지
LSTM(Long Short - Term Memory)
RNN의 문제
- RNN의 Vanishing Gradient 문제 : 관련 정보와 그 정보를 사용하는 지점 사이 거리가 멀 경우 gradient 감소로 학습 능력이 크게 저하
- RNN의 장기 의존성(long-term dependencies) 문제: 긴 기간 동안의 정보를 유지하고 활용하는 데 어려움 발생
- Cell State 업데이트
- Forget Gate : 불필요한 과거 잊기
- Input Gate : 현재 정보 중에서 중요한 것 기억
- Cell state 업데이트 : 위의 두 개를 결합하여 장기 기억 메모리에 태우기
- Hidden State 업데이트
- Hidden State는 과거의 hidden state를 받고 현시점의 입력 데이터를 고려하여 특징을 추출하는 역할
- output gate :
업데이트 된 Cell State와input, 이전 셀의 hidden state로 새 hidden state 값 생성해서 넘기기
실습
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN, LSTM, Flatten
from keras.backend import clear_session
from tensorflow.keras.optimizers import Adam
# 시계열 데이터 전처리 2차원 --> 3차원으로 변환
def temporalize(x, y, timesteps):
nfeature = x.shape[1]
output_x = []
output_y = []
for i in range(len(x) - timesteps + 1):
t = []
for j in range(timesteps):
t.append(x[[(i + j)], :])
output_x.append(t)
output_y.append(y[i + timesteps - 1])
return np.array(output_x).reshape(-1,timesteps, nfeature), np.array(output_y)
# 1. RNN 모델링
timesteps, nfeatures = x_train.shape[1], x_train.shape[2]
clear_session()
model = Sequential([SimpleRNN(8, input_shape = (timesteps, nfeatures), return_sequences = True),
SimpleRNN(8), Dense(1)])
model.summary()
# 2. LSTM 모델링
clear_session()
model = Sequential([LSTM(8, input_shape = (timesteps, nfeatures), return_sequences = True),
LSTM(8), Dense(1)])
model.summary()
참조
차원의 저주, 차원 축소
- 차원의 저주 : 변수의 수(차원의 수)가 늘어날수록 데이터가 희박해진다 → 학습이 적절하게 되지 않을 가능성이 높아짐
- 희박한 데이터 문제 해결방안
- 행 늘리기 : 데이터 늘리기
- 열 줄이기 : 차원 축소
- 차원 축소
- 기존 특성을 최대한 유지한 상태로 다수의 고차원 feature들을 소수의 저차원 feature로 축소
- 주성분 분석(PCA), t-SNE
- PCA
- 변수의 수보다 적은 저차원 평면으로 투영
- 분산을 최대한 유지하면서 차원 축소
- 절차
- 학습 데이터셋에서 분산이 최대인 첫번째 축(axis)을 찾음
- 첫번째 축과 직교(orthogonal)하면서 분산이 최대인 두 번째 축을 찾음
- 첫 번째 축과 두 번째 축에 직교하고 분산이 최대인 세 번째 축을 찾음
- 1 ~ 3번과 같은 방법으로 데이터셋의 차원 만큼의 축을 찾음
- 분석 수행 후, 각 축의 단위벡터 : 주성분(각 축 별 투영된 값 저장됨)
- PCA 사용하기
- 전처리 : 스케일링 필요
- PCA 문법
- 주성분의 개수 지정 후 fit & transform
- 개수를 늘려가면서 원본 데이터 분산과 비교(elbow method)
- 주성분의 개수 지정 후 fit & transform
