7주차 | 시각지능 딥러닝(CNN)(1)
KT AIVLE SCHOOL 5기 7주차에 진행한 시각지능 딥러닝(CNN) 강의 내용 정리 글입니다.
- Review
- Feature Representation
- Intro to Computer Vision
- CNN Basics
- Image Data Augmentation
- Pretrained CNN Model
- Transfer Learning
- 실습
Review
Feature Engineering 난이도 비교(ML vs DL)
- Tabular 데이터 : ML이 DL 보다 성능이 같거나 높음(이미 잘 처리되었다)
- 이미지, 텍스트 데이터 : DL이 더 좋다(수작업이 너무 힘들다)
- 상황에 따라 필요한 방법이 다르다
- 다양한 형태의 데이터(이미지, 텍스트, 음성 등)를 다루려면 Deep Learning
Feature Representation
- 연결된 것으로부터 새로운 Feature를 만듦(재표현)
- Hidden Layer의 노드 개별에 의한 설명은 알기 힘들다
- 이 노드가 예측이나 분류에 영향이 있는지
- 문제의 구도만 만들고서 성능 향상에 초점을 맞춰야 한다
- 노드 제거, 성능 유지 → 없어도 되는 feature
- 특정 히든 레이어에서 feature 증가 시켰더니 성능 향상 : feature 부족
- 히든 레이어 추가했더니 성능 향상 : 고수준 feature 부족
- Dense 의 수를 조절하고, 노드의 수를 조절
Intro to Computer Vision
- Pixel (픽셀): 화면을 구성하는 가장 기본이 되는 단위
- 필터를 CNN이 스스로 학습한다
CNN Basics
- Fully-Connected
- Flatten → 위치 정보의 손실
Convolutional Neural Networks
- Feature Map: Convolutional Layer를 거쳐 만들어진 서로 다른 Feature의 모임
- Convolutional Layer Filter sliding : 서로 다른 가중치의 필터들을 통해 Feature Map들을 만드는 과정
- Convolutional Layer Filter의 depth: 이전 Feature의 depth를 따라간다
- Stride : Filter의 이동 보폭 → Feature Map 크기에 영향
Padding : Feature Map 크기 유지, 외곽 정보 더 반영
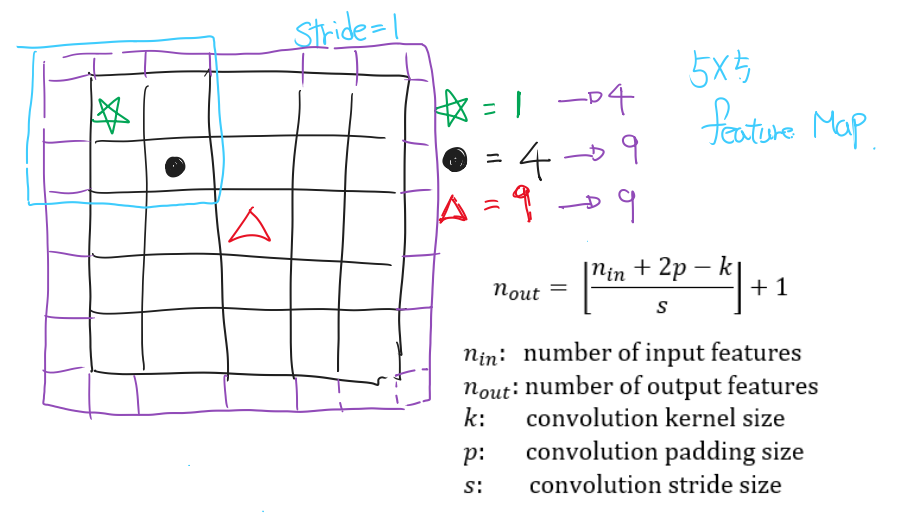
- Pooling Layer : Feature map 가로, 세로에만 영향(하드웨어 제약 : 연산량 감소를 위해)
- MaxPooling Layer : Relu + Pooling Layer (가장 큰 값을 가져감)
- LeNet-5 : Average Pooling Layer → 골고루 반영
- Pooling Filter size, stride : 기본적으로 stride는 size를 따라감
- MaxPooling Layer : Relu + Pooling Layer (가장 큰 값을 가져감)
Image Data Augmentation
- 부족한 데이터의 양을 늘리기 위해 사용되는 방법
- 학습 과정에서 데이터의 변형으로 다양성을 늘리기 위해 사용된다
결과적으로 위의 두 가지 방법을 통해 모델이 일반적인 상황에서 잘 동작하게 하려고 한다
- keras의 Data Augmentation 변화
- 예전에는 실제로 데이터를 증강시키면서 했지만 3.X 버전 부터는 변형으로 초점을 맞췄다
- Modeling과정에 Augmentation Layer 삽입
- 예전에는 실제로 데이터를 증강시키면서 했지만 3.X 버전 부터는 변형으로 초점을 맞췄다
- 모델 저장 및 로드
- 직접
save이용하여 저장 후load_model로 로드 가능 ModelCheckPoint로 저장시켜서load_model로 로드 가능
- 직접
Pretrained CNN Model
- 라이브러리 로딩으로 가져다 사용 가능
- 링크 : https://www.tensorflow.org/api_docs/python/tf/keras/applications
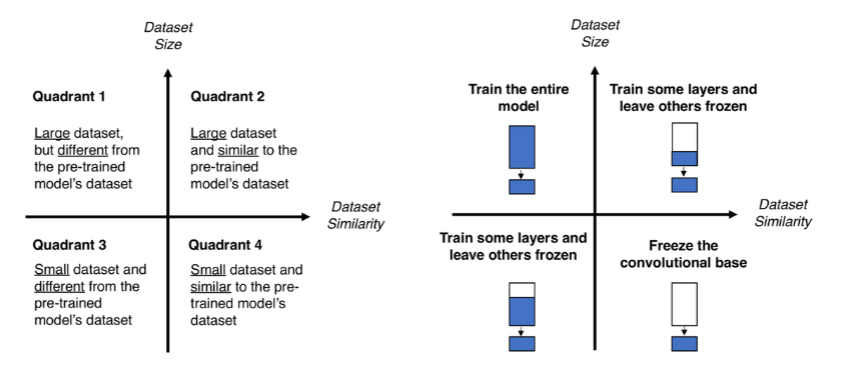
Transfer Learning
- Data Augmentation 사용의 문제점
- 원본과 확연히 다른 새로운 특징은 만들 수 없음
- 우리 문제 해결을 위해 사전 학습 모델을 변형 시켜 사용
- Pretrained CNN
- Fine Tuning
- Frozen : 가중치 update X
실습
# 1. 환경 설정
# 라이브러리 설치
!pip install --upgrade keras
# 라이브러리 설정
import os
os.environ['KERAS_BACKEND'] = 'tensorflow'
from keras.backend import clear_session
from keras.models import Sequential, Model
from keras.layers import Input, Dense, BatchNormalization, Dropout, Flatten, Conv2D, MaxPool2D
from keras.layers import RandomRotation, RandomTranslation, RandomFlip, RandomZoom
from keras.callbacks import EarlyStopping, ModelCheckpoint
# 2. Sequential API
# 1. 세션 클리어
clear_session()
# 2. 모델 선언
model1 = Sequential()
# 3. layer 추가
model1.add(Input(shape=(28, 28, 1)))
#########################################
model1.add(RandomRotation(0.2)) # 데이터 증강
#########################################
model1.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model1.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model1.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
model1.add(BatchNormalization())
model1.add(Dropout(0.25))
model1.add(Conv2D(filters=128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model1.add(Conv2D(filters=128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
model1.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
model1.add(BatchNormalization())
model1.add(Dropout(0.25))
model1.add(Flatten())
model1.add(Dense(10, activation='softmax'))
# 4. 모델 컴파일
model1.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model1.summary()
# 3. Functional API
# 1. 세션 클리어
clear_session()
# 2. layer 연결
il = Input(shape=(28, 28, 1))
#########################################
al = RandomRotation(0.2)(il) # 데이터 증강
#########################################
hl = Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(al)
hl = Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(hl)
hl = MaxPool2D(pool_size=(2, 2), strides=(2, 2))(hl)
hl = BatchNormalization()(hl)
hl = Dropout(0.25)(hl)
hl = Conv2D(filters=128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(hl)
hl = Conv2D(filters=128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')(hl)
hl = MaxPool2D(pool_size=(2, 2), strides=(2, 2))(hl)
hl = BatchNormalization()(hl)
hl = Dropout(0.25)(hl)
hl = Flatten()(hl)
ol = Dense(10, activation='softmax')(hl)
# 3. 모델 선언 및 컴파일
model2 = Model(il, ol)
model2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model2.summary()
# 4. 모델링
es = EarlyStopping(monitor='val_loss', min_delta=0, patience=5, verbose=1, restore_best_weights=True)
mcp = ModelCheckpoint(filepath='./model1.keras', # 모델 저장 경로
monitor='val_loss', # 모델 저장의 관심 대상
verbose=1, # 어느 시점에서 저장되는지 알려줌
save_best_only=True, # 최고 성능 모델만 저장
save_weights_only=False) # True : 가중치만 저장 .h5 | False : 모델 구조 포함하여 저장 .keras
history = model1.fit(train_x, train_y, validation_data=(val_x, val_y), epochs=10000, verbose=1, callbacks=[es, mcp])
# 5. 평가
performance_test = model1.evaluate(test_x, test_y)
print(f'Test Loss: {performance_test[0]:.6f}')
print(f'Test Accuracy: {performance_test[1]*100:.3f}%')
# 6. Model Save & Load
model1.save('./my_first_save.keras')
clear_session()
model3 = keras.models.load_model('./my_first_save.keras')
model3.summary()
# 1. Pretrained Model
from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
from keras.utils import plot_model
# 모델 가져오기
vgg_model = VGG16(include_top=True, # VGG16 모델의 아웃풋 레이어까지 전부 불러오기
weights='imagenet', # ImageNet 데이터를 기반으로 학습된 가중치 불러오기
input_shape=(224,224,3) # 모델에 들어가는 데이터의 형태
)
# 모델 시각화
plot_model(vgg_model, show_shapes=True, show_layer_names=True)
# 예측하기
features = vgg_model.predict(images)
predictions = decode_predictions(features, top=3)
for i in range(images.shape[0]) :
print(predictions[i])
plt.imshow(image.load_img(files[i]))
plt.show()
# 2. Transfer Learning
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.applications.inception_v3 import decode_predictions
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
from keras.preprocessing import image
from keras.utils import to_categorical
from keras.layers import GlobalAveragePooling2D, Dense
# Load Pretrained Model
keras.backend.clear_session()
base_model = InceptionV3(weights='imagenet', # ImageNet 데이터를 기반으로 미리 학습된 가중치 불러오기
include_top=False, # InceptionV3 모델의 아웃풋 레이어는 제외하고 불러오기
input_shape= (299,299,3)) # 입력 데이터의 형태
new_output = GlobalAveragePooling2D()(base_model.output)
new_output = Dense(3, # class 3개 클래스 개수만큼 진행한다.
activation = 'softmax')(new_output)
model = keras.models.Model(base_model.inputs, new_output)
model.summary()
# Fine-tuning
for idx, layer in enumerate(model.layers) :
if idx < 213 :
layer.trainable = False
else :
layer.trainable = True
# 처음부터 학습시키는 것도 아니고,
# 마지막 100개의 레이어만 튜닝 할 것이므로 learning rate를 조금 크게 잡아본다.
model.compile(loss='categorical_crossentropy', metrics=['accuracy'],
optimizer=keras.optimizers.Adam(learning_rate=0.001) )
# Learning rate reduction & Callbacks
lr_reduction = ReduceLROnPlateau(monitor='val_loss',
patience=4,
verbose=1,
factor=0.5,
min_lr=0.000001)
es = EarlyStopping(monitor='val_loss',
min_delta=0, # 개선되고 있다고 판단하기 위한 최소 변화량
patience=4, # 개선 없는 epoch 얼마나 기다려 줄거야
verbose=1,
restore_best_weights=True)
# 학습
# 데이터를 넣어서 학습시키자!
hist = model.fit(train_x, train_y,
validation_data=(valid_x, valid_y),
epochs=1000, verbose=1,
callbacks=[es, lr_reduction]
)
# 평가
model.evaluate(test_x, test_y) ## [loss, accuracy]
