7주차 | 시각지능 딥러닝(Object Detection)(2)
KT AIVLE SCHOOL 5기 7주차에 진행한 시각지능 딥러닝(Object Detection) 강의 내용 정리 글입니다.
- Conputer Vision Tasks & Datasets
- Object Detection
- UltraLytics : YOLO v8
- Roboflow Community
- Object Detection 실습
Conputer Vision Tasks & Datasets
- Image Classification
- MNIST, Fashion MNIST, CIFAR-10/100
- Object Detection
- Pascal VOC → MS COCO(현재의 기준)
- Oriented Bounding Boxes(Object Detection의 확장)
- DOTA(기울어진 Object Detection)
- Semantic Segmentation(픽셀 단위의 분류)
- CITYSCAPES
- Instance Segmentation(Object Detection + Semantic Segmentation)
- MS COCO
- Pose
- MS COCO
- Vision and Natural Language(image to text)
- MS COCO Captions
Object Detection
- Claasification + Localization
- Multi-Labeled Classification + Bounding Box Regression
- Localization: 단 하나의 Object 위치를 Bounding Box로 지정하여 찾음
- Bounding Box Regression: 여러 개의 Object 위치를 Bounding Box로 지정하여 찾음
- 주요 개념
- Bounding Box
- 하나의 Object가 포함된 최소 크기 박스(위치 정보)
- 모델이 Object가 있는 위치를 잘 예측한다(꼭지점, 크기 예측 Good)
- Class Classification
- Confidence Score
- Object가 Bounding Box 안에 있는 지에 대한 확신의 정도
- Predicted Bounding Box의 Confidence Score가 1에 가까울수록 Object가 있다고 판단
- 모델에 따라 계산이 조금씩 다름
- 단순히 Object가 있을 확률
- Object가 있을 확률 X IoU
- Object가 특정 클래스일 확률 X IoU
IOU(Intersection over Union)
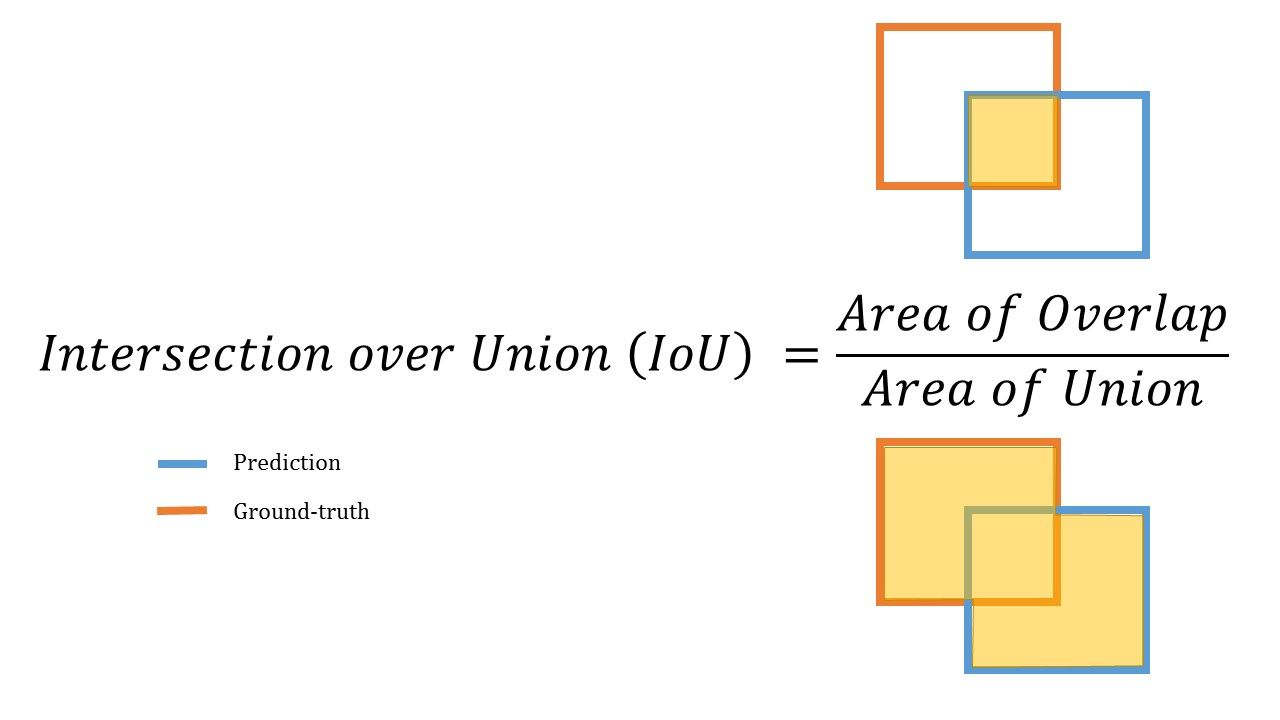
- 겹치는 영역이 넓을수록 좋음(0 ~ 1의 값, 값이 클수록 좋은 예측)
- NMS(Non-Maximum Suppression)
- 동일 Object에 대한 중복 박스 제거
- 과정
- 일정 Confidence Score 이하의 Bounding Box 제거
- 남은 Bounding Box들을 Confidence Score 내림차순으로 정렬
- 첫 Bounding Box(Confidence Score가 가장 높은)와의 IoU 값이 일정 이상인 박스들을 제거
- Bounding Box가 하나 될 때까지 반복
- Confidence Score Threshold가 높을수록, IoU Threshold가 낮을수록 → 박스에 대한 중복 판단이 깐깐해지는 것
- Confidence Score Threshold, IoU Threshold: 사용자가 조절하는 HyperParameter
- Precision, Recall, AP, mAP
- Precision, Recall
- Precision: TP / (TP + FP)
- 모델이 Object라 예측한 것 중 실제 Object의 비율
- Recall: TP / (TP + FN)
- 실제 Object 중 모델이 예측하여 맞춘 Object의 비율
- IoU Threshold 값에 따라 Precision, Recall 변화
- Precision: TP / (TP + FP)
- AP, mAP
- Precision - Recall Curve: Precision과 Recall을 모두 감안한 지표
- Average Precision (AP): Precision - Recall Curve 그래프 아래의 면적
- mean Average Precision(mAP): 각 클래스 별 AP를 합산하여 평균을 낸 것
- YOLO v8 → MS COCO: mAP[0.5 : 0.95], Pascal VOC: mAP[0.5] → 9 : 1로 평가에 사용
- Precision, Recall
- Annotation
- 이미지 내 Detection 정보를 별도의 설명 파일로 제공되는 것
- Annotation은 Object의 Bounding Box 위치나 Object 이름 등을 특정 포맷으로 제공
- YOLO: txt 형식으로 Annotation 파일 존재
- Bounding Box
- Neural Net 관점에서 지도 학습 : Error를 줄여나가는 방향으로 가중치 update
- CNN 은 Object Detection에서 위치 정보를 보존하여 feature represent하는 역할을 함
- Object Detection 모델의 구성
- Backbone(CNN 모델, 과거 Resnet 많이 사용)
- Neck
- Head(우리 문제에 맞게 변형)
UltraLytics : YOLO v8
- 사전 학습된 모델 : 직접 설치하여 사용 해야함
- 이미지 수집, Bounding Box 그리는 사전 작업 필요
- 모델 선언
- model : 모델 구조 또는 모델 구조 + 가중치 설정(task와 맞는 모델을 선택)
- task : detect, segment, classify, pose 중 택일
- 모델 학습
- 파라미터
- data : 학습시킬 데이터셋의 경로. default ‘coco128.yaml’
- epochs : 학습 데이터 전체를 총 몇 번씩 학습시킬 것인지 설정. default 100
- patience : 학습 과정에서 성능 개선이 발생하지 않을 때 몇 epoch 더 지켜볼 것인지 설정. default 50
- batch : 미니 배치의 사이즈 설정. default 16. -1일 경우 자동 설정.
- imgsz : 입력 이미지의 크기. default 640
- save : 학습 과정을 저장할 것인지 설정. default True
- project : 학습 과정이 저장되는 폴더의 이름.
- name : project 내부에 생성되는 폴더의 이름.
- exist_ok : 동일한 이름의 폴더가 있을 때 덮어씌울 것인지 설정. default False
- pretrained : 사전 학습된 모델을 사용할 것인지 설정. default False
- optimizer : 경사 하강법의 세부 방법 설정. default ‘auto’
- verbose : 학습 과정을 상세하게 출력할 것인지 설정. default False
- seed : 재현성을 위한 난수 설정
- resume : 마지막 학습부터 다시 학습할 것인지 설정. default False
- freeze : 첫 레이어부터 몇 레이어까지 기존 가중치를 유지할 것인지 설정. default None
- 파라미터
- 예측값 생성
- source : 예측 대상 이미지/동영상의 경로
- conf : confidence score threshold. default 0.25
- iou : NMS에 적용되는 IoU threshold. default 0.7. threshold를 넘기면 같은 object를 가리키는 거라고 판단.
- save : 예측된 이미지/동영상을 저장할 것인지 설정. default False
- save_txt : Annotation 정보도 함께 저장할 것인지 설정. default False
- save_conf : Annotation 정보 맨 끝에 Confidence Score도 추가할 것인지 설정. default False
- line_width : 그려지는 박스의 두께 설정. default None
Roboflow Community
- 남의 데이터셋 활용
- 직접 데이터셋 구성
- server가 좋지 않아 대안으로 Annotation tool인 Ybat Master 사용 가능
Object Detection 실습
이미지 조건
- 최소 클래스 3개 이상
- 한 이미지에 여러 클래스가 있으면 좋음
- non-iconic images 수집
데이터
- Hand_gun Detection
- 카테고리 : Handgun, Person, Person_with_gun
- Roboflow 사이트에서 사진 다운로드 후 직접 annotation 진행(271장의 이미지 데이터)
- 데이터 증강 및 전처리 적용하여 약 640장의 데이터셋 생성
- 데이터 : https://app.roboflow.com/ds/DNyLGrE8AB?key=shuS39jWKs
- jupyter notebook 링크를 복사해와서 다운로드하는 방법도 있다
모델링
# 1. 모델링 라이브러리 설치
!pip install ultralytics
from ultralytics import YOLO, settings
# 2. 데이터셋 경로 수정 & YAML 파일 경로 수정
settings['datasets_dir'] = '/content/' # Colab에서 진행
settings.update()
# YAML 파일 train, val 경로 수정 필요
# 3. 모델 구조에 사전 학습 가중치를 가져와서 사용
model2 = YOLO(model='yolov8s.pt', task='detect')
model2.train(data='/content/aivle5_last-2/data.yaml',
epochs=200,
patience=20,
pretrained=True,
verbose=True,
seed=2024,
)
results = model2.predict(source='/content/test_002.jpg',
save=True,
conf=0.5,
iou=0.5,
line_width=2)
- Confidence threshold, IOU threshold 각각 0.5로 설정하니 잘 맞춤
추후 필요 작업
- PC / Notebook Cam을 띄우고 YOLO 동작시키기
- Mobile에서도 YOLO 동작시키기(프론트엔드, 웹, 백엔드)
