8주차 | 4차 미니프로젝트
KT AIVLE SCHOOL 5기 8주차에 진행한 4차 미니프로젝트 내용 정리 글입니다.
1일차
주제
차량 공유 업체 차량 파손 여부 분류
도메인 이해
- 차량 공유 : 자동차 소유권 가지고 있는 주체가 서비스에 가입된 회원에게 시간 단위로 차량의 이용 권한을 제공하는 것
- 차량 공유 절차
- 예약하기 → 운행 기작 전 확인 → 운행 시작 후 확인
- 차량 상태 확인을 위한 외관 촬영 검수
- 차량 이미지 사진을 통해 파손된 차량을 식별하고 알려주는 서비스 필요(하루 평균 7~8만장 사진 사용)
문제 정의
- 차량 공유 업체에게 필요한 차량 파손 여부를 알려주는 서비스를 개발
데이터 전처리
- 데이터는
'abnormal': 303, 'normal': 302로 총 605장의 이미지 - 처음에 299 X 299로 불러옴 → 224 X 224로 바꿈
- x, y 데이터를 만들어주기 위해 배열로 바꾸어주고 train, test = 9 : 1 → train, val 9 : 1로 split
- train_x, val_x, test_x에 preprocess_input 적용
모델링
- 모델 1
- VGGNet 절반 정도 비슷한 구조로 모델링 (299 X 299)
성능 측정 결과(Colab)
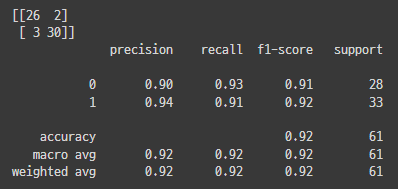
성능 측정 결과(Local)
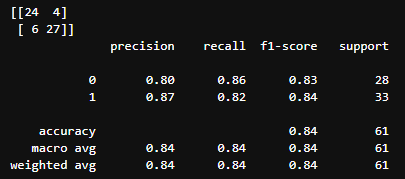
- 모델 2
- Inception V3 (299 X 299)
- image_dataset_from_directory을 이용하여 train_ds, val_ds 생성
- train_ds, val_ds에 preprocess_input 적용
- Inception V3 모델을 불러와서 분류기 제외 미리 학습된 가중치 load
- 불러온 모델의 모든 레이어 Frozen
성능 측정 결과(Colab)
1) Fine tuning으로 목적에 맞게 output layer와 연결 후 학습 진행
- Test Loss: 0.062309, Test Accuracy: 98.361%
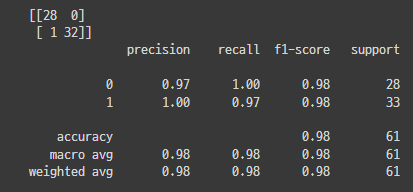
2) augmentation layer 추가
- accuracy는 비슷했지만 loss 0.1로 증가
3) learning rate 0.0001로 낮춤
- accuracy는 비슷했지만 loss 0.168로 증가
성능 측정 결과(Local)
1) Fine tuning으로 목적에 맞게 output layer와 연결 후 학습 진행
- Test Loss: 0.042640, Test Accuracy: 100.000%
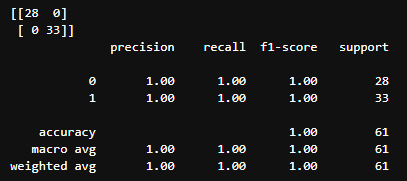
- Inception V3 (299 X 299)
2일차
데이터 전처리
- 데이터는
'abnormal': 303, 'normal': 302로 총 605장의 이미지 - 이미지 크기 224 X 224로 줄임(VGG16, VGG19)
모델링
- 모델 2
Inception V3 (224 X 224)
1) 기본
Test Loss: 0.083299, Test Accuracy: 96.721%
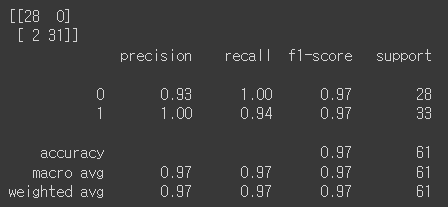
(299 X 299)에서 성능이 더 좋았다
- 모델 3
- VGG 16 (224 X 224)
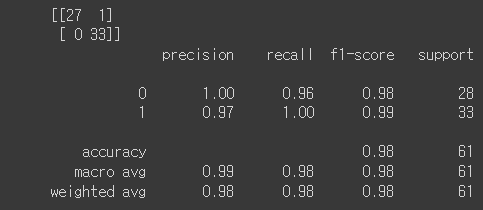
- 성능 측정 결과(Colab)
Test Loss: 0.088342, Test Accuracy: 98.361%
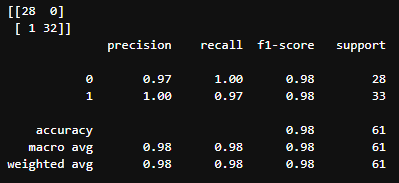
- 성능 측정 결과(Local)
Test Loss: 0.063890, Test Accuracy: 98.361%
- 성능 측정 결과(Colab)
- VGG 19 (224 X 224)
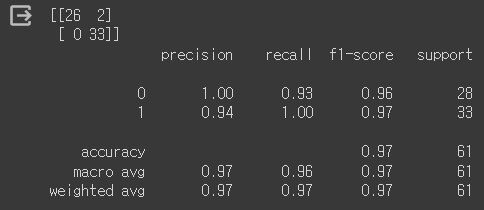
- 성능 측정 결과(Colab)
Test Loss: 0.065522, Test Accuracy: 96.721%
- 성능 측정 결과(Local)
Test Loss: 0.027519, Test Accuracy: 100.000%
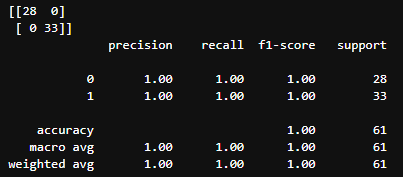
- 성능 측정 결과(Colab)
- VGG 16 (224 X 224)
다른 조들의 방법
- 다양한 증강 기법으로 이미지 데이터 증강
- 다양한 모델로 전이 학습 수행
- DeepSVDD라는 방법으로 파손 차량 검출 방식 사용 가능
결론
- Colab환경에서는 Inception V3(299 X 299)로 전이 학습한 결과가 가장 좋았다
- Local(데이터 스플릿 시 shuffle도 넣어주고, tensorflow, keras = 2.6.0 환경에서 진행)
- VGG19(224 X 224)로 전이 학습한 결과가 가장 좋았다
- 환경과 데이터 shuffle에 따라 학습 결과가 다른 것 같다
- 다양한 모델을 활용해서 전이 학습을 시도해봐야겠다
3일차
주제
- 인공위성 데이터로 도시 환경 개선
도메인 이해
- 쿨루프(Cool Roof) : 건물 지붕이나 옥상에 태양열 차단 효과가 있는 차열 페인트를 칠하여 건물에 열기가 축적되는 것을 줄이는 공법
- 쿨루프 옥상 표면은 15~30도, 실내 온도는 3~4도 감소 효과
- 쿨루프 사업 추진 간 현장을 확인해야 하는 어려움
- 시공 대상 여부를 효율적으로 식별할 수 있는 방법 필요
- 실제 사례 : 인공지능, 위성 영상 활용 ‘산림 벌채 탐지’ 세계 대회 우승
데이터 소개
- images(200개), labels 데이터들
- txt :
label, x, y, w, h
데이터 전처리
- 이미지, 라벨 파일 압축 해제 후 train, test = 9 : 1 → train, val 9 : 1로 split
- 각각의 images, labels 폴더로 이미지, 텍스트 파일들 이동
- YAML 파일 작성 → 일반 지붕으로 1로 설정(페인트 칠할 곳을 target으로 설정 해야 하기 때문)
모델링
yolov8s.pt모델로 학습 (epochs=200, patience=20)- precision, recall의 값은 0.8정도 나왔다
- 실제 test 데이터에 대해서는 잘 예측하지 못했다
추가 작업
- 추가적으로 데이터를 수집하여 학습 데이터의 양을 늘려야겠다
- oriented_bounding_box로도 접근해봐도 좋을 것 같다
4일차
학습 데이터 추가 수집
- 40장의 이미지 수집 후 annotation 진행
모델링
1) 수집한 40장의 이미지를 추가
yolov8s.pt모델로 학습 (epochs=200, patience=20)- precision, recall의 값은 0.7정도 나왔다
- 실제 test 데이터에 대해서는 데이터 추가 전보다 cool roof를 조금 더 잘 예측
yolov8m.pt모델로 학습 (epochs=200, patience=20)- small 모델보다 cool roof 더 잘 예측
- 너무 오래 걸린다(학습이 끊기지 않음)
2) 조원 들의 수집 데이터도 추가
- 총 760, 191개의 train, valid data
yolov8n.pt모델로 학습 (epochs=300, patience=20)- 최대한 많은 학습을 해봤다
- 학습시간이 너무 오래걸려 epoch 141에서 중단
- mAP50 : 0.91, mAP50-95 : 0.65 정도 나왔다
다른 조들의 방법
- 700개 이상의 데이터에서는 성능 저하 이슈가 있음, 300여개의 데이터로 진행 했을 때 mAP 약 0.93 나옴
- 실제 라벨링 이미지와 모델이 예측한 이미지를 비교하면 잘 확인 가능하다
- YOLO모델로 auto-labeling학습해서 라벨링 진행, Data augmentation 하이퍼파라미터 논문 참고하여 적용
- YOLOv8n.pt 모델을 epoch=1000, patience=30으로 줬을 때 mAP50 → 0.93 나옴
- mAP50-95를 보는 것이 좋다(실제로 성능 측정 시 mAP50-95를 90%정도 반영)
- .tune() 메서드로 자동으로 하이퍼파라미터 튜닝도 가능
느낀점
- 전이 학습의 전체적인 과정과 keras의 다양한 증강 및 전처리 layer들을 학습했다
- YOLOv8 모델의 다양한 기법 및 특징에 대해 제대로 파악할 수 있었다
- 우선 학습을 해보고 결과를 파악 해봐야 한다(섣부르게 판단하면 안된다)
- 어떤 수준의 모델을 어떻게 사용하는 지에 따라 성능의 차이가 난다
