DACON HD현대 AI Challenge
in Projects
DACON HD현대 AI Challenge 대회 진행 내용 정리 글입니다.
조선해양 분야 데이터를 기반으로 한 예측 알고리즘 구현 대회
0. 대회 요약
https://dacon.io/competitions/official/236158/overview/description
- 주최: HD한국조선해양 AI Center
- 운영: 데이콘
- 상금: 총 2000만원
- 주제: 항만 內 선박 대기 시간 예측을 위한 선박 항차 데이터 분석 AI 알고리즘 개발
- 평가 산식 : MAE (Mean Absolute Error, 평균 절대 오차)
- 기간: 2023.09.25 ~ 2023.10.30
- 팀 구성: 진깃, 광운인(본인) -2인
1. 데이터 구성
2012년부터 2022년까지의 약 10년치의 조선 해양 데이터
| Column | Description |
|---|---|
| ARI_CO | 도착항의 소속국가(도착항 앞 2글자) |
| ARI_PO | 도착항의 항구명(도착항 뒤 글자) |
| SHIP_TYPE_CATEGORY | 선종 통합 바탕으로 5대 선종으로 분류 |
| DIST | 정박지(ber_port)와 접안지 사이의 거리 |
| ATA | anc_port에 도착한 시점의 utc. 실제 정박 시각(Actual Time of Arrival) |
| ID | 선박식별 일련번호 |
| BREADTH | 선박의 폭 |
| BUILT | 선박의 연령 |
| DEADWEIGHT | 선박의 재화중량톤수 |
| DEPTH | 선박의 깊이 |
| DRAUGHT | 흘수 높이 |
| GT | 용적톤수(Gross Tonnage)값 |
| LENGTH | 선박의 길이 |
| SHIPMANAGER | 선박 소유주 |
| FLAG | 선박의 국적 |
| U_WIND | 풍향 u벡터 |
| V_WIND | 풍향 v벡터 |
| AIR_TEMPERATURE | 기온 |
| BN | 보퍼트 풍력 계급 |
| ATA_LT | anc_port에 도착한 시점의 현지 정박 시각(Local Time of Arrival)(단위 : H) |
| PORT_SIZE | 접안지 폴리곤 영역의 크기 |
| CI_HOUR | 대기시간 |
2. 데이터 탐색
Colab 환경에서 개발 진행
import & Data load
train, test 데이터셋의 SAMPLE_ID, ID 열 삭제 (불필요한 열 제거)
EDA
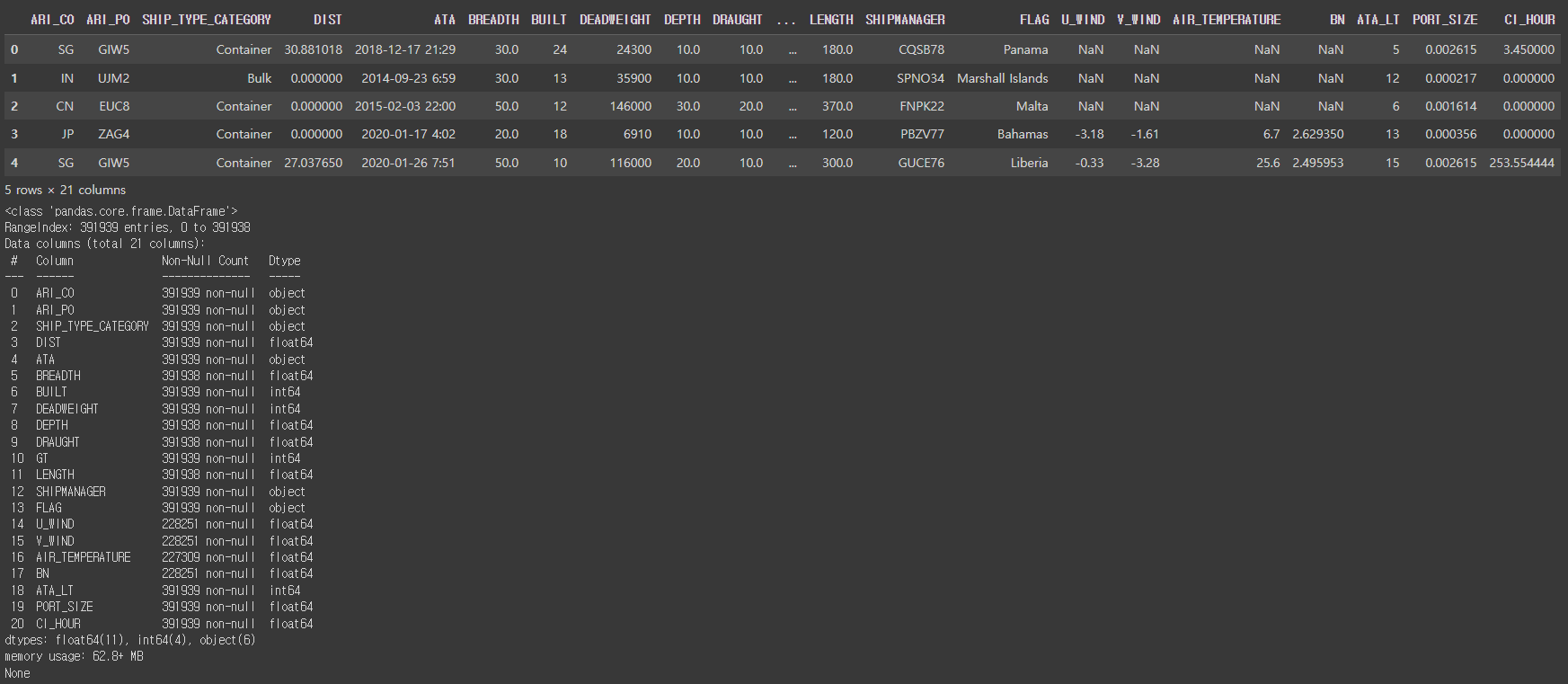
- 범주형 변수: ARI_CO, ARI_PO, SHIP_TYPE_CATEGORY ,SHIPMANAGER ,FLAG
- 수치형 변수: 나머지
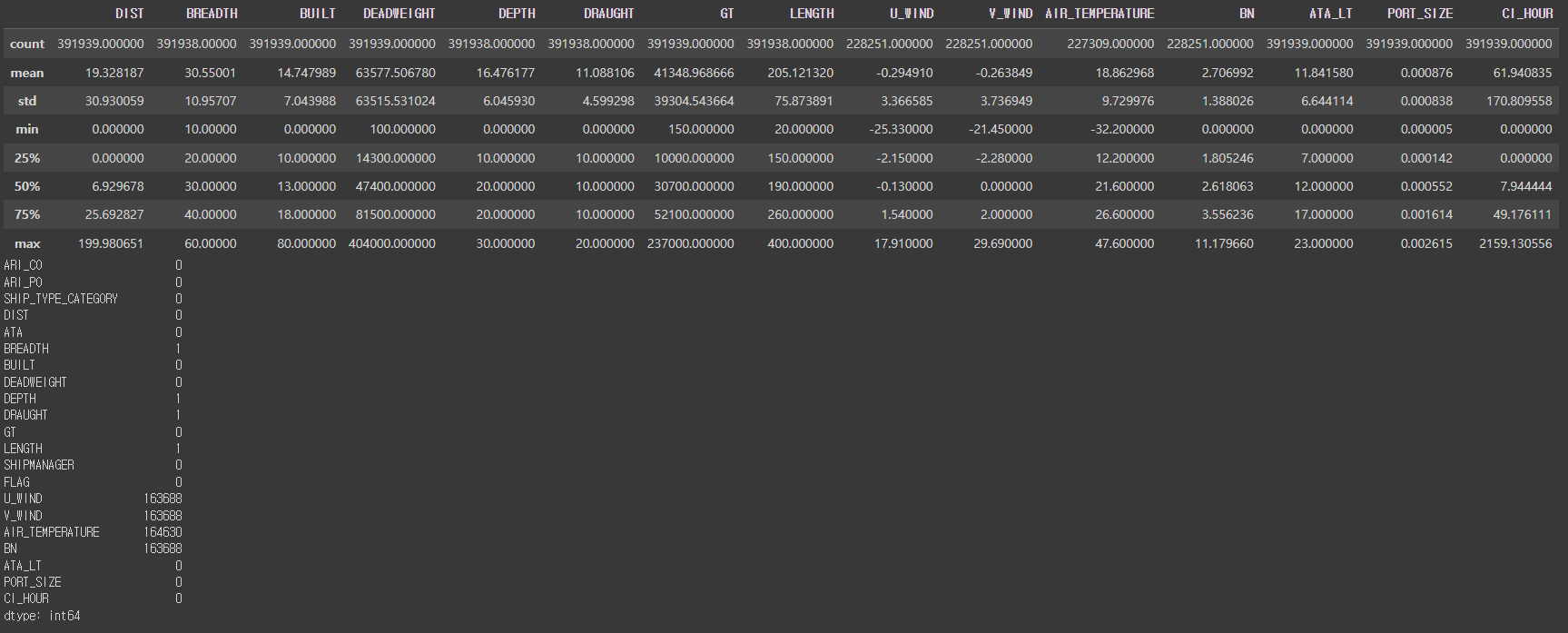
- 풍향 u,v벡터, 기온, 보퍼트 풍력 계급 변수에 결측치 존재
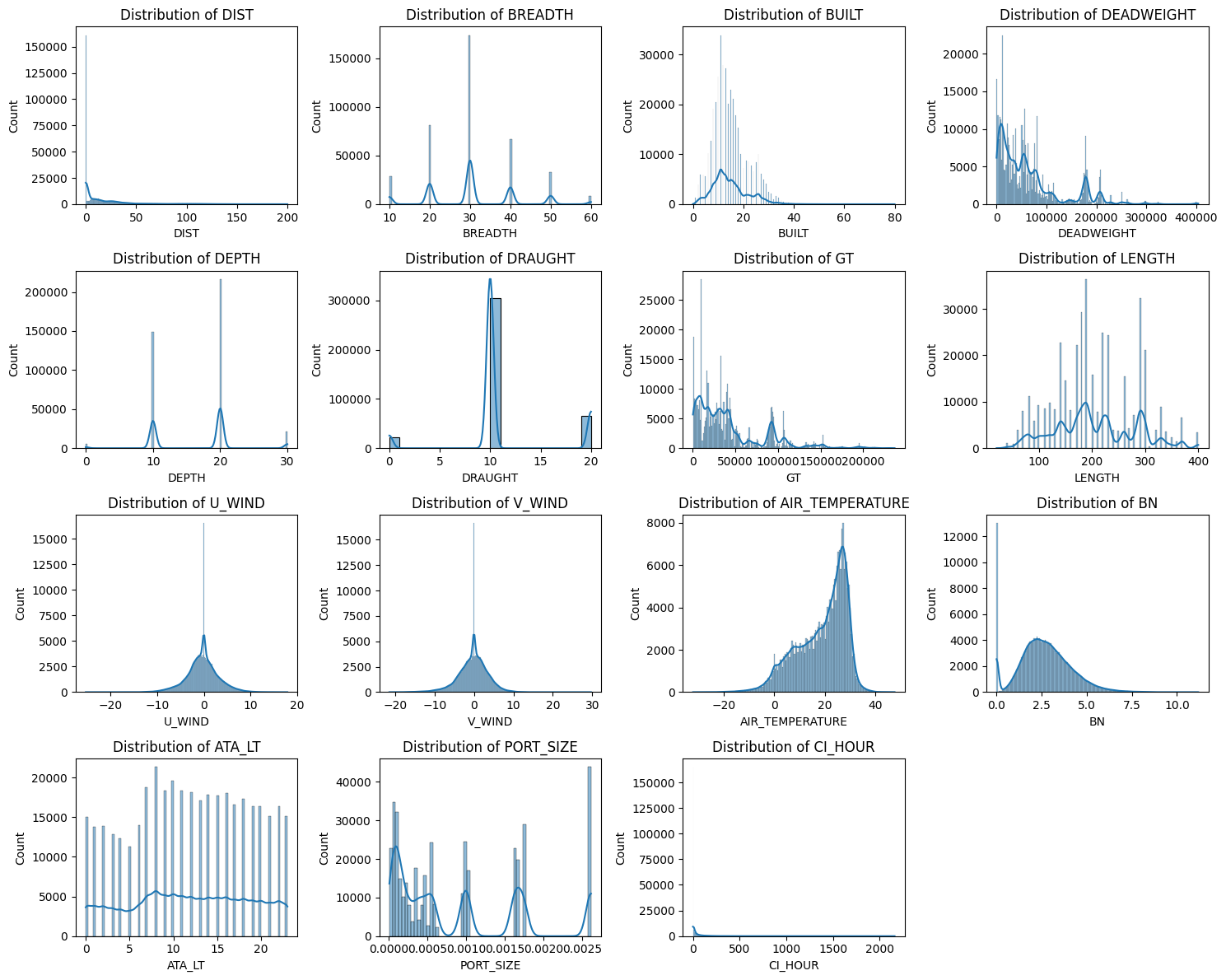
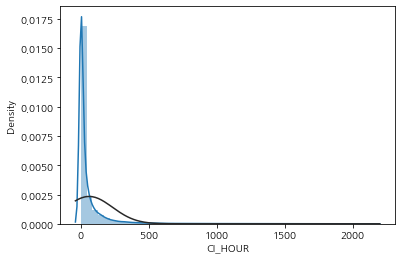
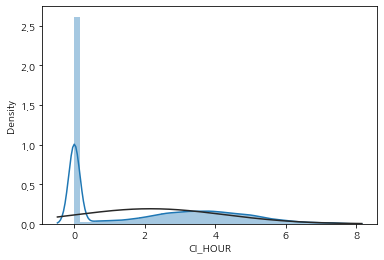
- 몇몇 수치형 데이터들의 경우 한쪽에 치우친 분포를 보임
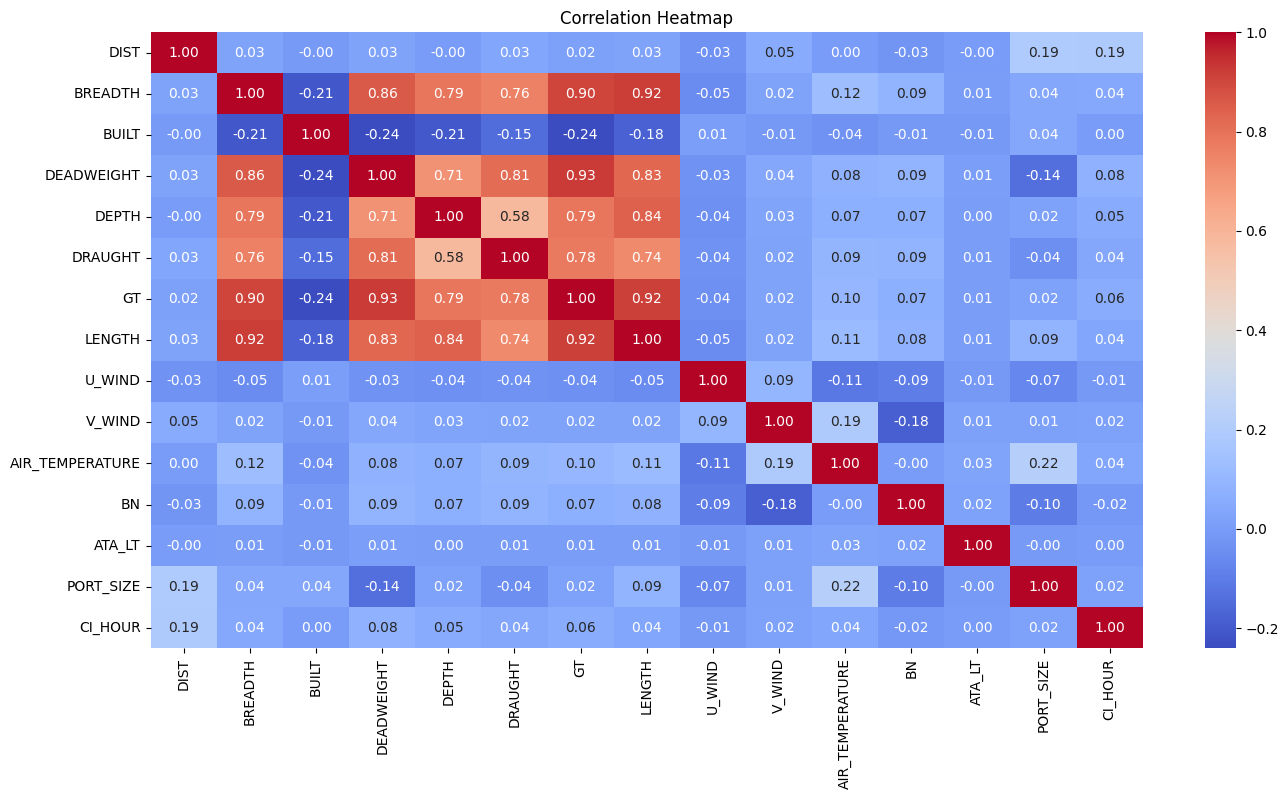
- DIST 변수가 제일 상관관계 높았지만 유의미한 수준이 아님
- 선박의 크기및 용적량 변수들 끼리의 상관계수 높게 측정
- breadth, deadweight, depth, draught, gt, length - [폭, 재화중량톤수, 깊이, 흘수높이, 용적톤수, 길이]
3. 데이터 전처리
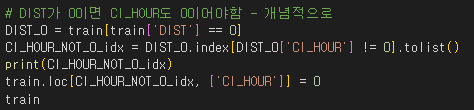


- 거리의 값이 0이면 대기시간은 당연히 0이 되야함
- BUILT, ATA_LT 컬럼 제거(종속변수와의 선형관계 0)
- 종속변수가 양의 왜도를 나타내고 정규성을 보장하기 위해 로그변환
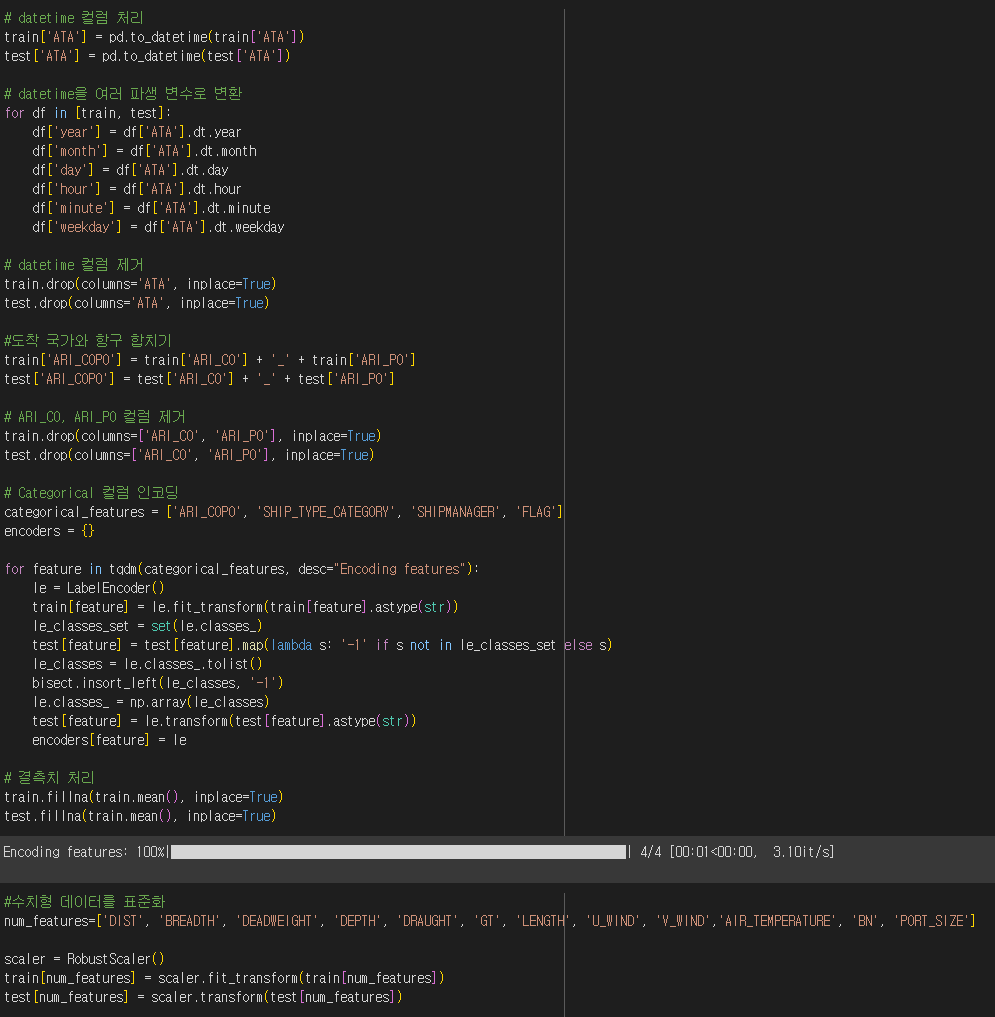
- 범주형 및 datetime 컬럼 처리
- 수치데이터 RobustScaler로 스케일링 (이상치에 덜 민감하게 하기 위해)
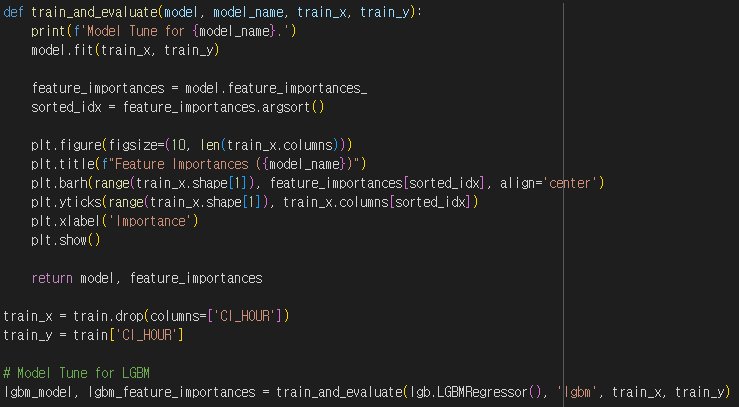
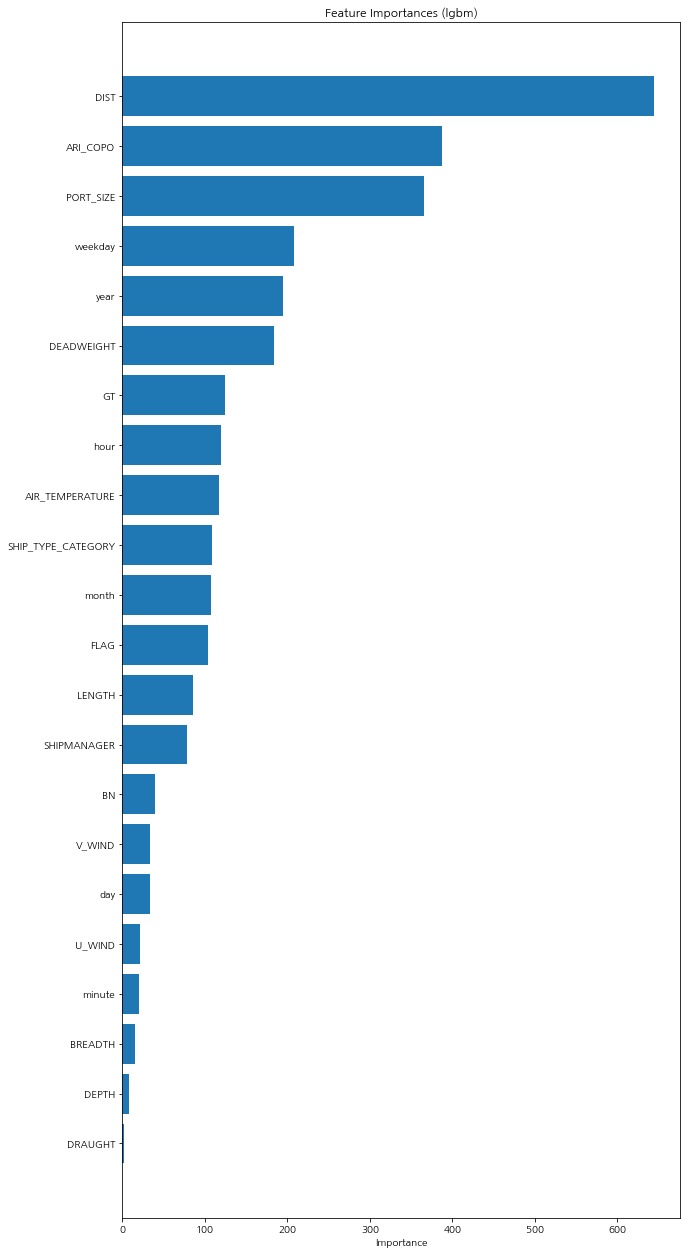
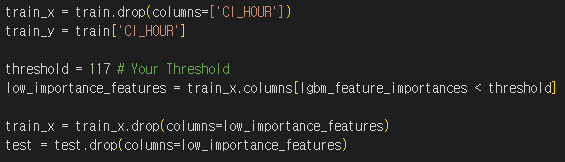
- LGBM 모델 특성 중요도로 특성 삭제 (중요도 상위 9개의 feature만 선택)
- 전처리된 데이터 저장
4. 모델 학습 및 검증
전처리된 데이터 로드
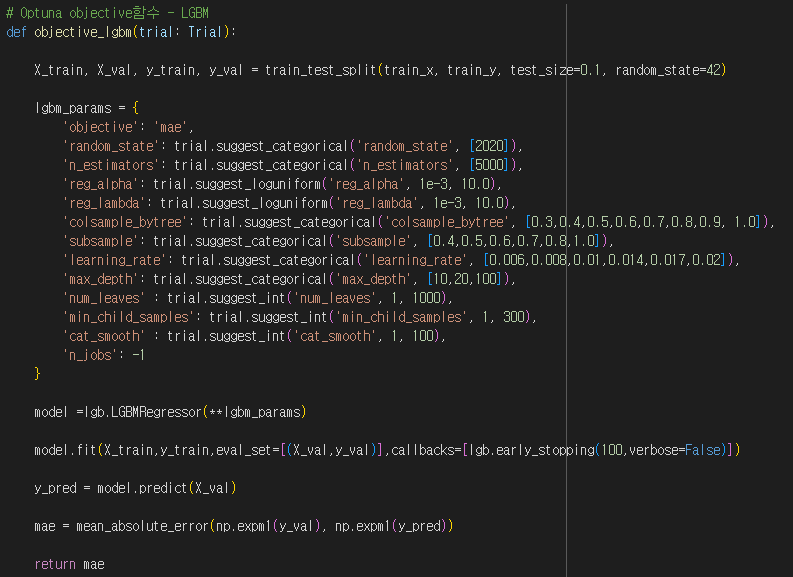


- 데이터의 수가 30만개 이상으로 많아 train, val 비율 9:1로 설정
- XGBoost, CatBoost, LGBM 모델 중에서 성능이 가장 좋은 LGBM 모델 채택
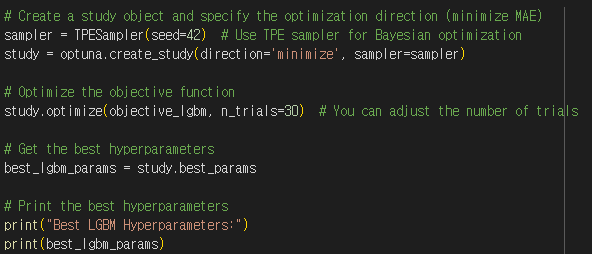
- Optuna 라이브러리 사용하여 LGBM 하이퍼 파라미터 최적화
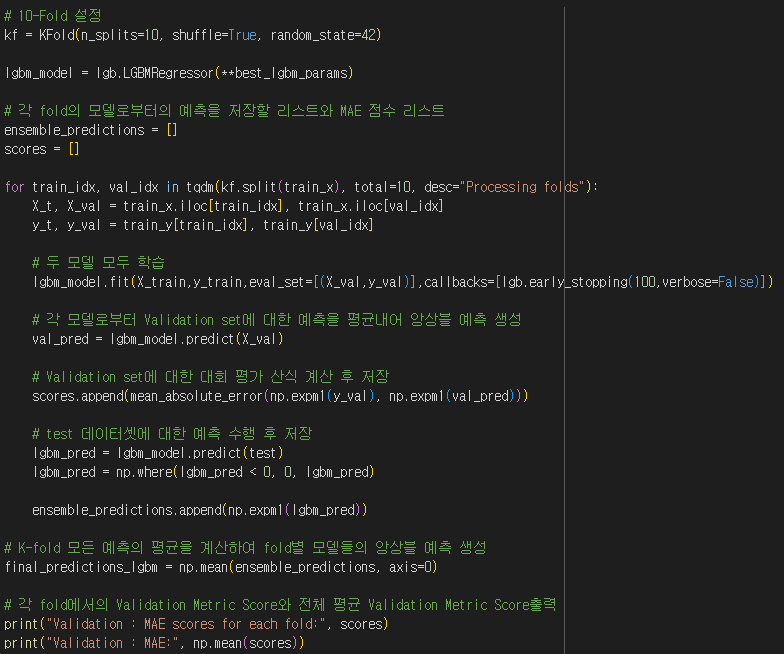
- 최적의 파라미터 적용시킨 LGBM 10 K-Fold 교차검증
- 검증 결과 평균 MAE 37.8968
5. 제출 및 결과
| Submission | CV MAE | Public MAE | Rank | Private MAE | Rank |
|---|---|---|---|---|---|
| 진깃 solution | - | 44.11155 | 64 / 349 | 44.018 | 57 /330 |
| 광운인 solution | 37.8968 | 44.2716 | - | - | - |
6. Lesson
- feature engineering, feature selection등의 처리와 교차검증 및 하이퍼 파라미터 최적화가 중요하다는 사실을 배웠다.
- 상위권의 팀들의 경우 AutoML, target encoding 등의 방법을 많이 사용했는데 이에 대해 학습이 필요할것 같다.
- 처음 대회치고 상당히 규모가 큰 대회에 참여했고 약 상위 18%의 결과를 보여줬다.
- DACON, Kaggle 등의 대회에 자주 참여해서 실력을 많이 키워나가야 할 것 같다.
