DACON 고객 대출등급 분류 해커톤
in Projects
DACON 고객 대출등급 분류 해커톤 대회 진행 내용 정리 글입니다.
고객의 대출등급을 예측하는 AI 알고리즘 구현 대회
- 대회 요약
- 0. import & data load
- 1. EDA
- 2. Data preprocessing
- 3. Model training & validation
- 4. Submission
- 결과
- Lesson
- 참조
대회 요약
https://dacon.io/competitions/official/236214/overview/description
- 주최: 데이콘
- 주관: 데이콘
- 주제: 고객의 대출등급을 예측하는 AI 알고리즘 개발
- 평가 산식 : Macro F1
- 기간: 2024.01.15 ~ 2024.02.05
- 팀 구성: 개인 참여
- 상금: 대회 1등부터 3등까지는 수상 인증서(Certification)가 발급
0. import & data load
# 공통 모듈 임포트
import numpy as np
import os
# 노트북 실행 결과를 동일하게 유지하기 위해
np.random.seed(42)
# 깔끔한 그래프 출력을 위해
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
import pandas as pd
# 시각화 패키지 불러오기
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from tqdm import tqdm
from scipy.stats import uniform, loguniform, randint
from sklearn.impute import SimpleImputer
from category_encoders.target_encoder import TargetEncoder
from sklearn.preprocessing import LabelEncoder,OneHotEncoder, StandardScaler
from sklearn.model_selection import StratifiedKFold, train_test_split, cross_val_score, RandomizedSearchCV, GridSearchCV
from sklearn.metrics import f1_score, make_scorer
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import (HistGradientBoostingClassifier, GradientBoostingClassifier, AdaBoostClassifier,
RandomForestClassifier, ExtraTreesClassifier)
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
from sklearn.neural_network import MLPClassifier
import optuna
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
DATA_DIR='data'
TRAIN_DIR=os.path.join(DATA_DIR, 'train.csv')
TEST_DIR=os.path.join(DATA_DIR, 'test.csv')
SUB_DIR=os.path.join(DATA_DIR, 'sample_submission.csv')
train=pd.read_csv(TRAIN_DIR)
test=pd.read_csv(TEST_DIR)
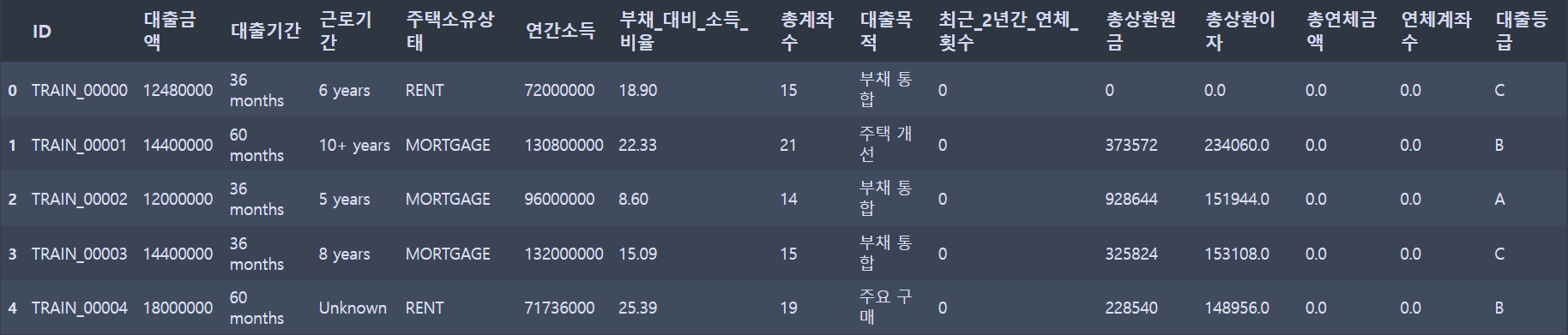
train.head()
1. EDA
데이터 복사:
loan=train.copy()
loan.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 96294 entries, 0 to 96293
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 96294 non-null object
1 대출금액 96294 non-null int64
2 대출기간 96294 non-null object
3 근로기간 96294 non-null object
4 주택소유상태 96294 non-null object
5 연간소득 96294 non-null int64
6 부채_대비_소득_비율 96294 non-null float64
7 총계좌수 96294 non-null int64
8 대출목적 96294 non-null object
9 최근_2년간_연체_횟수 96294 non-null int64
10 총상환원금 96294 non-null int64
11 총상환이자 96294 non-null float64
12 총연체금액 96294 non-null float64
13 연체계좌수 96294 non-null float64
14 대출등급 96294 non-null object
dtypes: float64(4), int64(5), object(6)
memory usage: 11.0+ MB
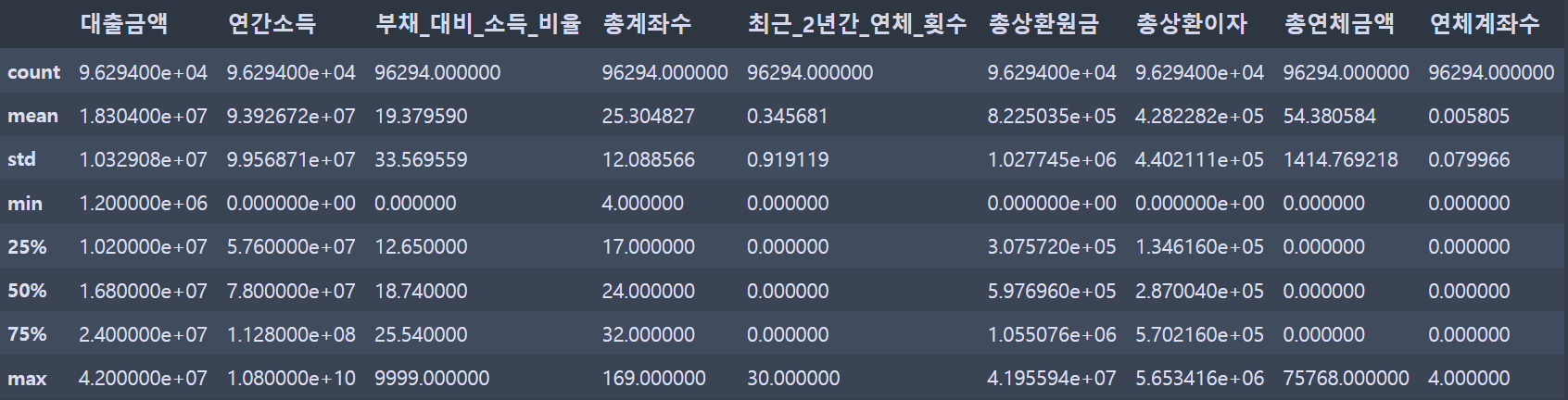
loan.describe()
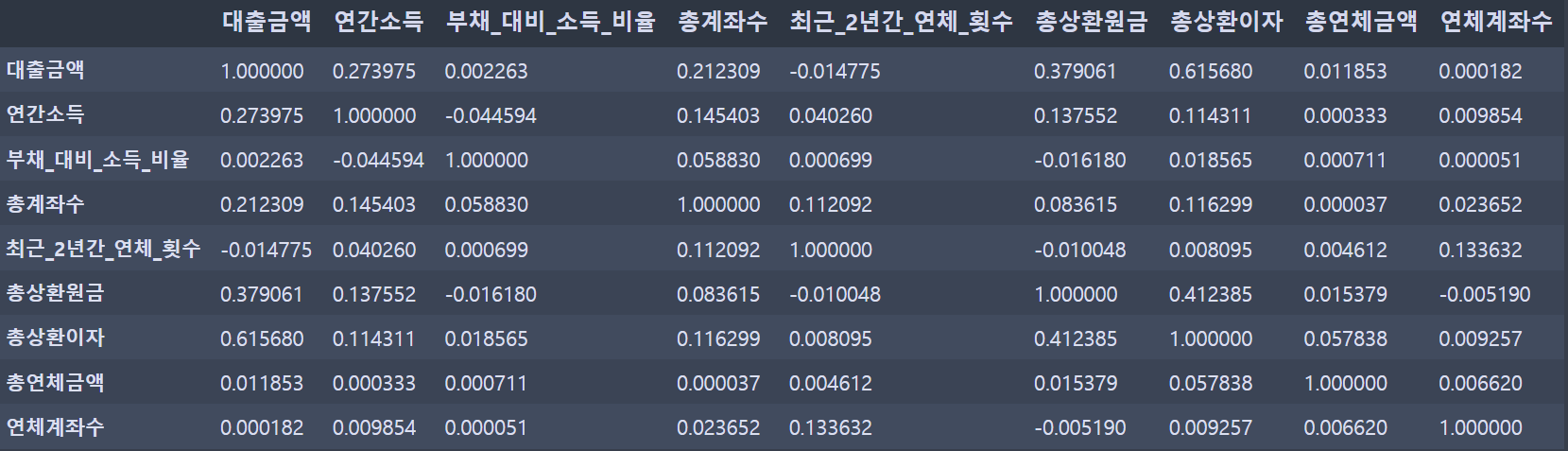
상관관계 조사:
numerical_features = ['대출금액', '연간소득', '부채_대비_소득_비율', '총계좌수', '최근_2년간_연체_횟수', '총상환원금', '총상환이자', '총연체금액', '연체계좌수']
corr_matrix = loan[numerical_features].corr()
corr_matrix
zero_count1 = (loan['최근_2년간_연체_횟수'] == 0).sum()
zero_count2 = (loan['총연체금액'] == 0).sum()
zero_count3 = (loan['연체계좌수'] == 0).sum()
print("최근_2년간_연체_횟수가 0인 행의 개수:", zero_count1)
print("총연체금액이 0인 행의 개수:", zero_count2)
print("연체계좌수가 0인 행의 개수:", zero_count3)
최근_2년간_연체_횟수가 0인 행의 개수: 76392
총연체금액이 0인 행의 개수: 96113
연체계좌수가 0인 행의 개수: 95762
연간소득,부채_대비_소득_비율,총상환원금,총상환이자,최근_2년간_연체_횟수,총연체금액,연체계좌수특성들의 0값은 대체 필요 (중앙값 or 평균값)연간소득:대출금액와 상관관계 높음부채_대비_소득_비율:총계좌수와 상관관계 높음총상환이자:대출금액와 상관관계 높음총상환원금:총상환이자와 상관관계 높음최근_2년간_연체_횟수:총계좌수와 상관관계 높음총연체금액:총상환이자와 상관관계 높음연체계좌수:최근_2년간_연체_횟수와 상관관계 높음
%matplotlib inline
# 한글 폰트 설정하기
fe = fm.FontEntry(fname = 'NanumGothic.ttf', name = 'NanumGothic')
fm.fontManager.ttflist.insert(0, fe)
plt.rc('font', family='NanumGothic')
loan.hist(bins=50, figsize=(12,12))
plt.show()
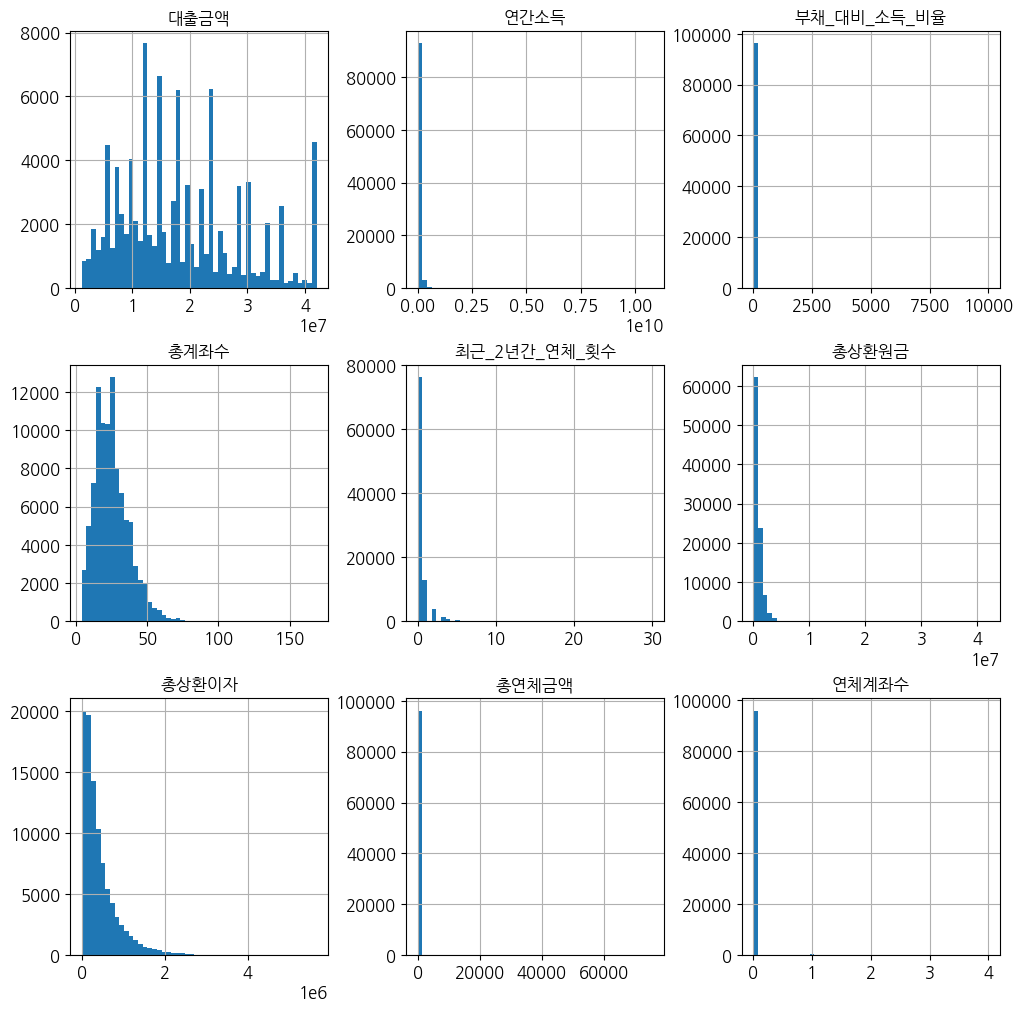
수치형 데이터들은 대체로 왼쪽으로 치우친 모습을 보여준다. (스케일링 및 변환 필요)
fig, axes = plt.subplots(3, 2, figsize=(30,25)) # 2x2 형식으로 4개 그래프 동시에 표시
sns.countplot(x = loan['대출기간'], ax=axes[0][0]).set_title('대출기간')
sns.countplot(x = loan['근로기간'], ax=axes[0][1]).set_title('근로기간')
sns.countplot(x = loan['주택소유상태'], ax=axes[1][0]).set_title('주택소유상태')
sns.countplot(x = loan['대출목적'], ax=axes[1][1]).set_title('대출목적')
sns.countplot(x = loan['대출등급'], ax=axes[2][0]).set_title('대출등급')
plt.show()
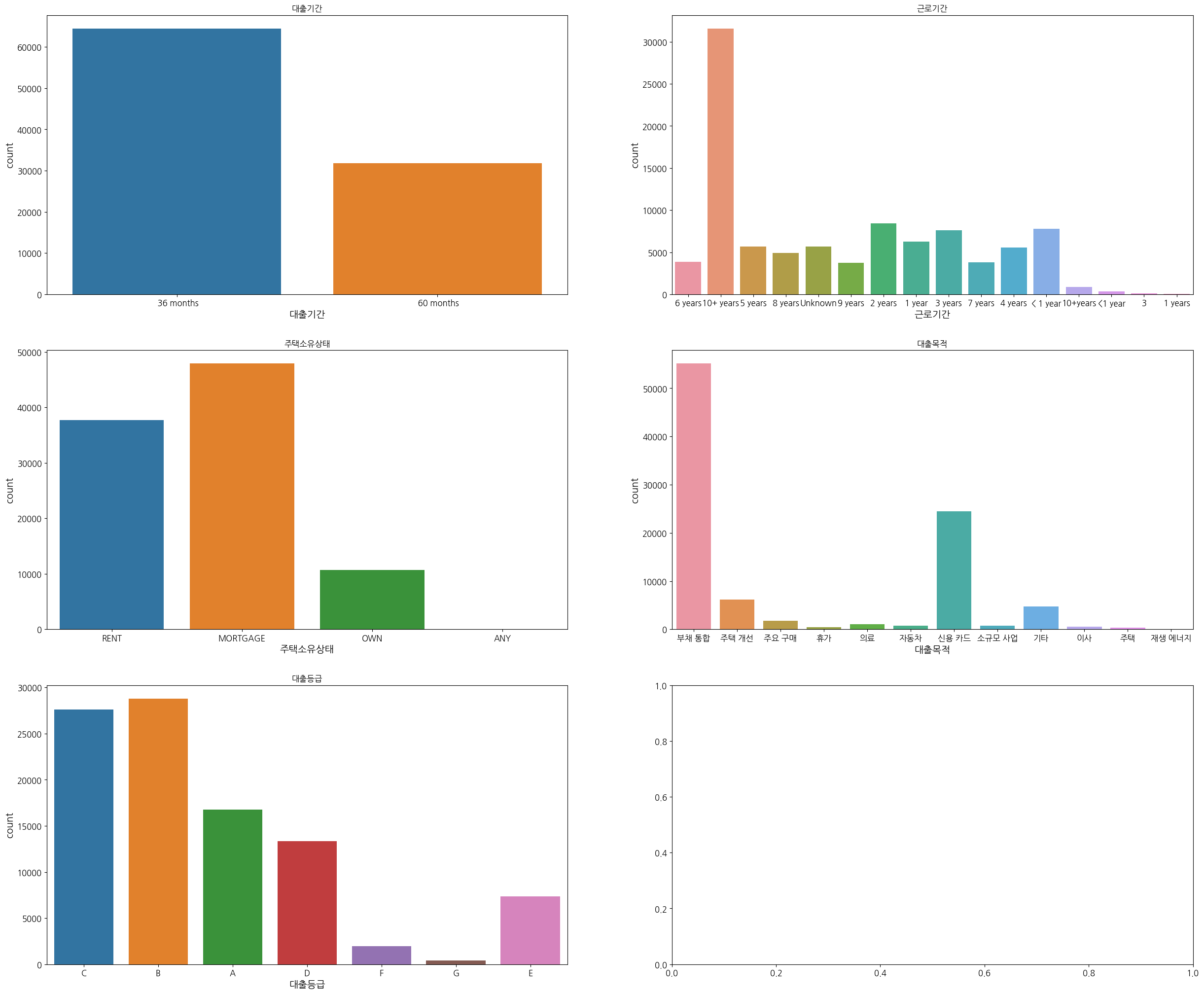
loan['주택소유상태'].value_counts()
MORTGAGE 47934
RENT 37705
OWN 10654
ANY 1
Name: 주택소유상태, dtype: int64
주택소유상태 특성의 ANY 최빈값으로 대체 필요
loan['근로기간'].value_counts()
10+ years 31585
2 years 8450
< 1 year 7774
3 years 7581
1 year 6249
Unknown 5671
5 years 5665
4 years 5588
8 years 4888
6 years 3874
7 years 3814
9 years 3744
10+years 896
<1 year 370
3 89
1 years 56
Name: 근로기간, dtype: int64
근로기간특성들의 같은 카테고리 끼리 통합,unknown값은 최빈값으로 대체 필요ID열은 불필요하므로 삭제 필요
특성 조합 테스트:
# 새로운 특성 조합 생성
loan['연간소득_대비_대출금액'] = loan['대출금액'] / loan['연간소득'] # 대출금액 대비 연간소득 비율
loan['부채_대비_소득_비율X연간소득'] = loan['부채_대비_소득_비율'] * loan['연간소득'] # 부채 대비 소득 비율에 연간소득을 곱한 값
loan['총상환원금+총상환이자'] = loan['총상환원금'] + loan['총상환이자'] # 총 상환원금과 총 상환이자의 합
loan['계좌당_평균_상환액'] = loan['총상환원금+총상환이자'] / loan['총계좌수'] # 계좌당 평균 상환액
loan['연간소득_대비_총연체금액'] = loan['총연체금액'] / loan['연간소득'] # 연간소득_대비_연체금액
2. Data preprocessing
변환기 및 Pipeline 생성
loan_x=train.drop("대출등급",axis=1) # 훈련 세트를 위해 레이블 제거
loan_labels=train["대출등급"].copy()
LightGBMClassifier 베이스라인 모델 & 교차검증 함수:
# LightGBM 베이스라인 모델
lgbm_baseline = LGBMClassifier(n_estimators=1000, max_depth=10, random_state=42)
def evaluate_lgbm_baseline(X, y, cv_folds=3):
stratified_kfold = StratifiedKFold(n_splits=cv_folds, shuffle=True, random_state=42)
macro_f1_scorer = make_scorer(f1_score, average='macro')
cv_scores = cross_val_score(lgbm_baseline, X, y, cv=stratified_kfold, scoring=macro_f1_scorer)
print("Baseline Mean Macro F1 Score:", cv_scores.mean())
return cv_scores.mean()
수치형 특성 중 0인값 -> NaN 변환기:
class ZeroToNaNConverter(BaseEstimator, TransformerMixin):
def __init__(self, features):
self.features = features
def fit(self, X, y=None):
return self
def transform(self, X):
X_transformed = X.copy()
X_transformed[self.features] = X_transformed[self.features].replace(0, np.nan)
return X_transformed
범주형 열 삭제 및 처리 변환기:
class CategoricalFeatureProcessor(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
# 주택소유상태의 최빈값
self.homeownership_mode = X['주택소유상태'].mode()[0]
# 근로기간의 동의어를 통합
mapping = {
'10+ years': '10+ years',
'10+years': '10+ years',
'< 1 year': '< 1 year',
'<1 year': '< 1 year',
'1 year': '1 year',
'1 years': '1 year',
'2 years': '2 years',
'3 years': '3 years',
'3' : '3 years',
'4 years': '4 years',
'5 years': '5 years',
'6 years': '6 years',
'7 years': '7 years',
'8 years': '8 years',
'9 years': '9 years',
'unknown': X['근로기간'].mode()[0], # 'unknown' 값을 최빈값으로 대체
}
self.mapping = mapping
return self
def transform(self, X):
# 주택소유상태의 'ANY' 값을 최빈값으로 대체
X['주택소유상태'] = X['주택소유상태'].replace('ANY', self.homeownership_mode)
# 띄어쓰기와 대소문자 통일
X['근로기간'] = X['근로기간'].str.lower().str.strip()
# 근로기간의 동의어를 통합
X['근로기간'] = X['근로기간'].map(self.mapping)
# ID 열 제거
X = X.drop(['ID'], axis=1)
return X
범주형 특성 변환기:
class CustomLabelEncoder(BaseEstimator, TransformerMixin):
def __init__(self, categorical_features):
self.categorical_features = categorical_features
self.label_encoders = {}
def fit(self, X, y=None):
for feature in self.categorical_features:
le = LabelEncoder()
le.fit(X[feature])
self.label_encoders[feature] = le
return self
def transform(self, X):
X_transformed = X.copy()
for feature, le in self.label_encoders.items():
# test 데이터셋에서 이전에 보지 못한 라벨 처리
test_unseen_labels = np.setdiff1d(X[feature], le.classes_)
if len(test_unseen_labels) > 0:
le.classes_ = np.concatenate([le.classes_, test_unseen_labels])
X_transformed[feature] = le.transform(X[feature])
return X_transformed
특성 조합 변환기:
numerical_features = ['대출금액', '연간소득', '부채_대비_소득_비율', '총계좌수', '최근_2년간_연체_횟수', '총상환원금', '총상환이자', '총연체금액', '연체계좌수']
class FeatureCombiner(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
new_feature1 = X[:, 0] / X[:, 1] # 대출금액_대비_연간소득
new_feature2 = X[:, 0] / X[:, 2] # 대출금액_대비_부채_대비_소득_비율
new_feature3 = X[:, 0] / X[:, 3] # 대출금액_대비_총계좌수
new_feature4 = X[:, 0] / X[:, 4] # 대출금액_대비_최근_2년간_연체_횟수
new_feature5 = X[:, 1] / X[:, 2] # 연간소득_대비_부채_대비_소득_비율
new_feature6 = X[:, 1] / X[:, 3] # 연간소득_대비_총계좌수
new_feature7 = X[:, 1] / X[:, 4] # 연간소득_대비_최근_2년간_연체_횟수
new_feature8 = X[:, 2] / X[:, 3] # 부채_대비_소득_비율_대비_총계좌수
new_feature9 = X[:, 2] / X[:, 4] # 부채_대비_소득_비율_대비_최근_2년간_연체_횟수
new_feature10 = X[:, 3] / X[:, 4] # 총계좌수_대비_최근_2년간_연체_횟수
new_feature11 = X[:, 2] * X[:, 1] # 부채_대비_소득_비율X연간소득
new_feature12 = X[:, 5] + X[:, 6] # 총상환원금+총상환이자
new_feature13 = (X[:, 5] + X[:, 6]) / X[:, 3] # 계좌당_평균_상환액
new_feature14 = X[:, 7] / X[:, 1] # 총연체금액_대비_연간소득
return np.c_[X, new_feature1, new_feature2, new_feature3, new_feature4, new_feature5, new_feature6, new_feature7, new_feature8, new_feature9,
new_feature10, new_feature11, new_feature12, new_feature13, new_feature14]
파이프라인 설계:
# 수치형 변수와 범주형 변수의 이름 리스트
numerical_features = ['대출금액', '연간소득', '부채_대비_소득_비율', '총계좌수', '최근_2년간_연체_횟수', '총상환원금', '총상환이자', '총연체금액', '연체계좌수']
categorical_features = ['ID', '대출기간', '주택소유상태', '근로기간', '대출목적']
# 수치형 파이프라인 구축
numerical_pipeline = Pipeline([
('zero_to_NaN', ZeroToNaNConverter(numerical_features)),
('imputer', SimpleImputer(strategy="median")),
('feature_combiner', FeatureCombiner()),
('std_scaler', StandardScaler())
])
# 범주형 변수 처리 파이프라인
categorical_pipeline = Pipeline([
('feature_processor', CategoricalFeatureProcessor()),
('label_encoder', CustomLabelEncoder(categorical_features=['대출기간', '주택소유상태', '근로기간', '대출목적']))
])
# ColumnTransformer를 사용하여 수치형 변수와 범주형 변수를 처리
full_pipeline = ColumnTransformer([
('num', numerical_pipeline, numerical_features),
('cat', categorical_pipeline, categorical_features)
])
# loan 데이터프레임에 전체 파이프라인을 적용
loan_prepared = full_pipeline.fit_transform(loan_x)
loan_prepared
array([[-0.56384797, -0.22022729, -0.0143855 , ..., 2. ,
6. , 1. ],
[-0.37796396, 0.37032541, 0.08779393, ..., 0. ,
1. , 10. ],
[-0.61031897, 0.02081463, -0.32122171, ..., 0. ,
5. , 1. ],
...,
[-0.37796396, -0.09970633, -0.24257631, ..., 0. ,
0. , 3. ],
[-0.26178646, -0.27717344, -0.06204938, ..., 0. ,
5. , 1. ],
[-0.93561598, -0.43716502, -0.22589396, ..., 2. ,
1. , 3. ]])
loan_prepared.shape
(96294, 27)
evaluate_lgbm_baseline(loan_prepared, loan_labels) # 결과 경고 메시지 제거
Baseline Mean Macro F1 Score: 0.7806581869797552
0.7806581869797552
3. Model training & validation
랜덤 탐색 및 특성 선택
아래의 분류 모델들 교차검증으로 성능 파악:
def evaluate_models(X, y):
models = {
'DecisionTreeClassifier': DecisionTreeClassifier(random_state=42),
'XGBClassifier': XGBClassifier(random_state=42, eval_metric='merror'),
'LGBMClassifier': LGBMClassifier(random_state=42),
'CatBoostClassifier': CatBoostClassifier(random_state=42),
}
for model_name, model in models.items():
f1_macro_scorer = make_scorer(f1_score, average='macro')
scores = cross_val_score(model, X, y, cv=5, scoring=f1_macro_scorer)
mean_f1_macro = scores.mean()
std_f1_macro = scores.std()
print(f"{model_name} 모델의 성능 (Macro F1):")
print(f"평균 Macro F1 Score: {mean_f1_macro:.4f}")
print(f"표준편차 Macro F1 Score: {std_f1_macro:.4f}")
print()
# Usage
evaluate_models(loan_prepared, loan_labels)
DecisionTreeClassifier 모델의 성능 (Macro F1):
평균 Macro F1 Score: 0.7476
표준편차 Macro F1 Score: 0.0028
XGBClassifier 모델의 성능 (Macro F1):
평균 Macro F1 Score: 0.7958
표준편차 Macro F1 Score: 0.0051
LGBMClassifier 모델의 성능 (Macro F1):
평균 Macro F1 Score: 0.7730
표준편차 Macro F1 Score: 0.0049
CatBoostClassifier 모델의 성능 (Macro F1):
평균 Macro F1 Score: 0.7336
표준편차 Macro F1 Score: 0.0044
속도 빠른 LGBMClassifier 모델 랜덤탐색 수행:
# 모델 정의
lgb_clf = LGBMClassifier(device='gpu')
# 탐색할 파라미터 공간 정의
lgb_param_dist = {
'objective': ['multiclass'],
'metric': ['multi_logloss'],
'boosting_type': ['gbdt', 'dart'],
'learning_rate': loguniform(0.001, 0.1),
'max_depth': randint(3, 15),
'min_child_samples': randint(1, 10),
'subsample': uniform(0.7, 0.3),
'colsample_bytree': uniform(0.7, 0.3),
'reg_alpha': loguniform(1e-8, 1.0),
'reg_lambda': loguniform(1e-8, 1.0),
'n_estimators': randint(100, 500),
'random_state': [42],
}
# 평가 지표 정의
f1_macro_scorer = make_scorer(f1_score, average='macro')
# RandomizedSearchCV를 사용하여 하이퍼파라미터 탐색
random_search = RandomizedSearchCV(
lgb_clf, param_distributions=lgb_param_dist, n_iter=10,
scoring=f1_macro_scorer, cv=5, random_state=42
)
# 모델 훈련
random_search.fit(loan_prepared, loan_labels)
# 결과 출력
print("Best Hyperparameters:", random_search.best_params_) # 결과 경고 메시지 제거
print("Best Macro F1 Score:", random_search.best_score_)
File "C:\Users\pjj11\anaconda3\envs\test3.7\lib\site-packages\joblib\externals\loky\backend\context.py", line 230, in _count_physical_cores
cpu_info = cpu_info.stdout.decode('utf-8').splitlines()
Best Hyperparameters: {'boosting_type': 'gbdt', 'colsample_bytree': 0.8803345035229626, 'learning_rate': 0.026070247583707663, 'max_depth': 8, 'metric': 'multi_logloss', 'min_child_samples': 5, 'n_estimators': 357, 'objective': 'multiclass', 'random_state': 42, 'reg_alpha': 0.0059702178437701465, 'reg_lambda': 0.32241977615440703, 'subsample': 0.7002336297523043}
Best Macro F1 Score: 0.7770803533099638
LGBMClassifier 특성중요도:
feature_importances=random_search.best_estimator_.feature_importances_
feature_importances
array([ 5247, 564, 952, 529, 49, 20895, 19893, 280, 0,
1570, 922, 877, 2093, 918, 775, 890, 1064, 680,
741, 1146, 7314, 1197, 605, 2935, 302, 477, 1725])
feature_importances=np.array([ 5247, 564, 952, 529, 49, 20895, 19893, 280, 0,
1570, 922, 877, 2093, 918, 775, 890, 1064, 680,
741, 1146, 7314, 1197, 605, 2935, 302, 477, 1725])
특성들과 특성중요도 매칭:
extra_attribs = ['대출금액_대비_연간소득', '대출금액_대비_부채_대비_소득_비율', '대출금액_대비_총계좌수', '대출금액_대비_최근_2년간_연체_횟수', '연간소득_대비_부채_대비_소득_비율', '연간소득_대비_총계좌수',
'연간소득_대비_최근_2년간_연체_횟수', '부채_대비_소득_비율_대비_총계좌수', '부채_대비_소득_비율_대비_최근_2년간_연체_횟수', '총계좌수_대비_최근_2년간_연체_횟수', '부채_대비_소득_비율X연간소득', '총상환원금+총상환이자',
'계좌당_평균_상환액', '총연체금액_대비_연간소득']
num_attribs = ['대출금액', '연간소득', '부채_대비_소득_비율', '총계좌수', '최근_2년간_연체_횟수', '총상환원금', '총상환이자', '총연체금액', '연체계좌수']
cat_attribs = ['대출기간', '주택소유상태', '근로기간', '대출목적']
attributes=num_attribs + extra_attribs + cat_attribs
sorted(zip(feature_importances, attributes), reverse=True)
[(20895, '총상환원금'),
(19893, '총상환이자'),
(7314, '총상환원금+총상환이자'),
(5247, '대출금액'),
(2935, '대출기간'),
(2093, '대출금액_대비_최근_2년간_연체_횟수'),
(1725, '대출목적'),
(1570, '대출금액_대비_연간소득'),
(1197, '계좌당_평균_상환액'),
(1146, '부채_대비_소득_비율X연간소득'),
(1064, '부채_대비_소득_비율_대비_총계좌수'),
(952, '부채_대비_소득_비율'),
(922, '대출금액_대비_부채_대비_소득_비율'),
(918, '연간소득_대비_부채_대비_소득_비율'),
(890, '연간소득_대비_최근_2년간_연체_횟수'),
(877, '대출금액_대비_총계좌수'),
(775, '연간소득_대비_총계좌수'),
(741, '총계좌수_대비_최근_2년간_연체_횟수'),
(680, '부채_대비_소득_비율_대비_최근_2년간_연체_횟수'),
(605, '총연체금액_대비_연간소득'),
(564, '연간소득'),
(529, '총계좌수'),
(477, '근로기간'),
(302, '주택소유상태'),
(280, '총연체금액'),
(49, '최근_2년간_연체_횟수'),
(0, '연체계좌수')]
특성중요도 기준 상위 k개 특성 선택 변환기:
def indices_of_top_k(arr, k):
return np.sort(np.argpartition(np.array(arr), -k)[-k:])
class TopFeatureSelector(BaseEstimator, TransformerMixin):
def __init__(self, feature_importances, k):
self.feature_importances = feature_importances
self.k = k
def fit(self, X, y=None):
self.feature_indices_ = indices_of_top_k(self.feature_importances, self.k)
return self
def transform(self, X):
return X[:, self.feature_indices_]
k = 5
top_k_feature_indices = indices_of_top_k(feature_importances, k)
top_k_feature_indices
array([ 0, 5, 6, 20, 23], dtype=int64)
np.array(attributes)[top_k_feature_indices]
array(['대출금액', '총상환원금', '총상환이자', '총상환원금+총상환이자', '대출기간'], dtype='<U27')
sorted(zip(feature_importances, attributes), reverse=True)[:k]
[(20895, '총상환원금'),
(19893, '총상환이자'),
(7314, '총상환원금+총상환이자'),
(5247, '대출금액'),
(2935, '대출기간')]
LGBMClassifier랜덤 탐색으로 탐색한 가장 좋은 성능을 보인 파라미터 선택- 전처리 + 특성 선택 + 예측 파이프라인 구축
- 그리드 탐색으로 결측값 대체 + 특성 선택을 수행하여 최고의 성능을 보일 때를 탐색
lgbm_params={'boosting_type': 'gbdt', 'colsample_bytree': 0.8803345035229626, 'learning_rate': 0.026070247583707663, 'max_depth': 8, 'metric': 'multi_logloss',
'min_child_samples': 5, 'n_estimators': 357, 'objective': 'multiclass', 'random_state': 42, 'reg_alpha': 0.0059702178437701465, 'reg_lambda': 0.32241977615440703, 'subsample': 0.7002336297523043, 'device':'gpu'}
prepare_select_and_predict_pipeline = Pipeline([
('preparation', full_pipeline),
('feature_selection', TopFeatureSelector(feature_importances, k)),
('lgbm_clf', LGBMClassifier(**lgbm_params))
])
f1_macro_scorer = make_scorer(f1_score, average='macro')
param_grid = [{
'preparation__num__imputer__strategy': ['mean', 'median', 'most_frequent'],
'feature_selection__k': list(range(1, len(feature_importances) + 1))
}]
grid_search_prep = GridSearchCV(prepare_select_and_predict_pipeline, param_grid, cv=5,
scoring=f1_macro_scorer)
grid_search_prep.fit(loan_x, loan_labels) # 결과 경고 메시지 제거
File "C:\Users\pjj11\anaconda3\envs\test3.7\lib\site-packages\joblib\externals\loky\backend\context.py", line 230, in _count_physical_cores
cpu_info = cpu_info.stdout.decode('utf-8').splitlines()
GridSearchCV(cv=5,
estimator=Pipeline(steps=[('preparation',
ColumnTransformer(transformers=[('num',
Pipeline(steps=[('zero_to_NaN',
ZeroToNaNConverter(features=['대출금액',
'연간소득',
'부채_대비_소득_비율',
'총계좌수',
'최근_2년간_연체_횟수',
'총상환원금',
'총상환이자',
'총연체금액',
'연체계좌수'])),
('imputer',
SimpleImputer(strategy='median')),
('feature_combiner',
FeatureCombiner()),
('std_scaler',
StandardS...
objective='multiclass',
random_state=42,
reg_alpha=0.0059702178437701465,
reg_lambda=0.32241977615440703,
subsample=0.7002336297523043))]),
param_grid=[{'feature_selection__k': [1, 2, 3, 4, 5, 6, 7, 8, 9,
10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 27],
'preparation__num__imputer__strategy': ['mean',
'median',
'most_frequent']}],
scoring=make_scorer(f1_score, average=macro))
grid_search_prep.best_params_
{'feature_selection__k': 5, 'preparation__num__imputer__strategy': 'mean'}
최상위 5개 특성과 mean으로 0값 대체 했을 때 가장 좋은 성능 보임
k = 5
top_k_feature_indices = indices_of_top_k(feature_importances, k)
top_k_feature_indices
array([ 0, 5, 6, 20, 23], dtype=int64)
np.array(attributes)[top_k_feature_indices]
array(['대출금액', '총상환원금', '총상환이자', '총상환원금+총상환이자', '대출기간'], dtype='<U27')
전처리 데이터셋에서 상위 5개 특성만 추출:
loan_total_prepared=loan_prepared[:, [ 0, 5, 6, 20, 23]]
loan_total_prepared.shape
(96294, 5)
optuna 하이퍼파라미터 튜닝
XGBClassifier 모델 optuna 로 하이퍼파라미터 튜닝:
X_train, X_val, y_train, y_val = train_test_split(loan_total_prepared, loan_labels, test_size=0.1, random_state=42)
def objective(trial: optuna.Trial):
xgb_params = {
'objective': 'multi:softmax',
'eval_metric': 'merror',
'booster': trial.suggest_categorical('booster', ['gbtree', 'gblinear', 'dart']),
'learning_rate': trial.suggest_loguniform('learning_rate', 0.001, 0.1),
'max_depth': trial.suggest_int('max_depth', 6, 12),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 5),
'subsample': trial.suggest_uniform('subsample', 0.8, 1.0),
'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.8, 1.0),
'gamma': trial.suggest_loguniform('gamma', 1e-8, 1.0),
'reg_alpha': trial.suggest_loguniform('reg_alpha', 1e-8, 1.0),
'reg_lambda': trial.suggest_loguniform('reg_lambda', 1e-8, 1.0),
'n_estimators': trial.suggest_int('n_estimators', 250, 450),
'scale_pos_weight': trial.suggest_float('scale_pos_weight', 0.1, 5.0),
'max_delta_step': trial.suggest_float('max_delta_step', 0, 5),
'sampling_method': trial.suggest_categorical('sampling_method', ['uniform', 'gradient_based']),
'tree_method': 'gpu_hist',
'random_state': 42
}
model = XGBClassifier(**xgb_params, verbosity=0)
model.fit(X_train, y_train, eval_set=[(X_val, y_val)], early_stopping_rounds=100, verbose=False)
y_pred = model.predict(X_val)
macro_f1 = f1_score(y_val, y_pred, average='macro')
return macro_f1
def optimize_xgb():
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)
best_params = study.best_params
best_macro_f1 = study.best_value
print(f"Best Macro F1 Score: {best_macro_f1:.4f}")
print("Best Parameters:")
print(best_params)
optimize_xgb()
[I 2024-02-05 14:04:29,390] A new study created in memory with name: no-name-2e80e917-b8ec-4b70-ad44-a577148d7365
[I 2024-02-05 14:05:52,280] Trial 0 finished with value: 0.7798224397225805 and parameters: {'booster': 'gbtree', 'learning_rate': 0.002090726124331091, 'max_depth': 9, 'min_child_weight': 1, 'subsample': 0.9964033692110036, 'colsample_bytree': 0.9737298436251411, 'gamma': 1.5184346245170606e-06, 'reg_alpha': 0.0007192931694395704, 'reg_lambda': 3.323166553041763e-08, 'n_estimators': 287, 'scale_pos_weight': 1.1906603125631756, 'max_delta_step': 2.8370322359244455, 'sampling_method': 'uniform'}. Best is trial 0 with value: 0.7798224397225805.
[I 2024-02-05 14:14:03,153] Trial 1 finished with value: 0.65770976959558 and parameters: {'booster': 'dart', 'learning_rate': 0.0013860809510680835, 'max_depth': 6, 'min_child_weight': 2, 'subsample': 0.982213071183677, 'colsample_bytree': 0.8286573447385354, 'gamma': 0.4284384653058455, 'reg_alpha': 2.742182266085689e-05, 'reg_lambda': 3.292452803733505e-07, 'n_estimators': 397, 'scale_pos_weight': 4.7119370421145295, 'max_delta_step': 3.551188073560227, 'sampling_method': 'uniform'}. Best is trial 0 with value: 0.7798224397225805.
[I 2024-02-05 14:15:06,460] Trial 2 finished with value: 0.8279466860568895 and parameters: {'booster': 'gbtree', 'learning_rate': 0.0384361989699588, 'max_depth': 10, 'min_child_weight': 3, 'subsample': 0.9873762544458636, 'colsample_bytree': 0.848272940903559, 'gamma': 0.023949540827846415, 'reg_alpha': 1.560094566424733e-08, 'reg_lambda': 0.048377790497836595, 'n_estimators': 283, 'scale_pos_weight': 2.318677740534382, 'max_delta_step': 2.725840969358906, 'sampling_method': 'uniform'}. Best is trial 2 with value: 0.8279466860568895.
[I 2024-02-05 14:15:12,354] Trial 3 finished with value: 0.27070069981506584 and parameters: {'booster': 'gblinear', 'learning_rate': 0.05664705700590662, 'max_depth': 10, 'min_child_weight': 4, 'subsample': 0.806296047582281, 'colsample_bytree': 0.9041678151593601, 'gamma': 0.04871296221786758, 'reg_alpha': 1.4493022747969289e-08, 'reg_lambda': 4.3909004402965285e-08, 'n_estimators': 332, 'scale_pos_weight': 0.2223035709693204, 'max_delta_step': 0.40145940653290135, 'sampling_method': 'gradient_based'}. Best is trial 2 with value: 0.8279466860568895.
[I 2024-02-05 14:15:48,218] Trial 4 finished with value: 0.7803400186671252 and parameters: {'booster': 'gbtree', 'learning_rate': 0.010739252647599395, 'max_depth': 7, 'min_child_weight': 1, 'subsample': 0.8090000993588351, 'colsample_bytree': 0.8172733153038472, 'gamma': 4.553606991589013e-05, 'reg_alpha': 7.221731375020129e-05, 'reg_lambda': 3.9231579544353436e-05, 'n_estimators': 349, 'scale_pos_weight': 2.1814235353640434, 'max_delta_step': 4.284084134495968, 'sampling_method': 'gradient_based'}. Best is trial 2 with value: 0.8279466860568895.
[I 2024-02-05 14:17:44,689] Trial 5 finished with value: 0.7908807694909894 and parameters: {'booster': 'gbtree', 'learning_rate': 0.0034859276243481177, 'max_depth': 10, 'min_child_weight': 5, 'subsample': 0.9859628984669883, 'colsample_bytree': 0.875866038990239, 'gamma': 3.029158557613961e-07, 'reg_alpha': 5.9871306092776935e-05, 'reg_lambda': 0.33026911167435685, 'n_estimators': 434, 'scale_pos_weight': 4.316615614668986, 'max_delta_step': 4.052035760428591, 'sampling_method': 'uniform'}. Best is trial 2 with value: 0.8279466860568895.
[I 2024-02-05 14:20:50,343] Trial 6 finished with value: 0.8077326548524463 and parameters: {'booster': 'gbtree', 'learning_rate': 0.004226590252552986, 'max_depth': 11, 'min_child_weight': 4, 'subsample': 0.9569396413613865, 'colsample_bytree': 0.8334103506385881, 'gamma': 0.0010827266303633093, 'reg_alpha': 0.02748880349731379, 'reg_lambda': 1.9274202121395957e-05, 'n_estimators': 448, 'scale_pos_weight': 0.9261254884391174, 'max_delta_step': 2.600706732458641, 'sampling_method': 'uniform'}. Best is trial 2 with value: 0.8279466860568895.
[I 2024-02-05 14:26:10,832] Trial 7 finished with value: 0.740955114401349 and parameters: {'booster': 'dart', 'learning_rate': 0.0013057075619586382, 'max_depth': 11, 'min_child_weight': 5, 'subsample': 0.8599720240339118, 'colsample_bytree': 0.8357423669004005, 'gamma': 0.0008979648946447752, 'reg_alpha': 0.0030124413975283365, 'reg_lambda': 1.8283425358540474e-06, 'n_estimators': 266, 'scale_pos_weight': 0.33993159808512313, 'max_delta_step': 1.0189876228327295, 'sampling_method': 'gradient_based'}. Best is trial 2 with value: 0.8279466860568895.
[I 2024-02-05 14:27:03,082] Trial 8 finished with value: 0.8345546063353166 and parameters: {'booster': 'gbtree', 'learning_rate': 0.0543481605978748, 'max_depth': 9, 'min_child_weight': 2, 'subsample': 0.8227629067103266, 'colsample_bytree': 0.9274922452701428, 'gamma': 6.378732831043594e-05, 'reg_alpha': 6.0932515963417545e-05, 'reg_lambda': 4.871754658697852e-07, 'n_estimators': 312, 'scale_pos_weight': 2.298163519990221, 'max_delta_step': 1.0064465163276681, 'sampling_method': 'uniform'}. Best is trial 8 with value: 0.8345546063353166.
[I 2024-02-05 14:27:08,368] Trial 9 finished with value: 0.16083591071057177 and parameters: {'booster': 'gblinear', 'learning_rate': 0.0013393285280090207, 'max_depth': 10, 'min_child_weight': 1, 'subsample': 0.8496689325671262, 'colsample_bytree': 0.8461218131380613, 'gamma': 0.0007140179841947302, 'reg_alpha': 0.0015332043938956433, 'reg_lambda': 0.0006174976856133092, 'n_estimators': 319, 'scale_pos_weight': 4.236860456212392, 'max_delta_step': 4.426413555964824, 'sampling_method': 'uniform'}. Best is trial 8 with value: 0.8345546063353166.
[I 2024-02-05 14:27:14,805] Trial 10 finished with value: 0.2502188581304294 and parameters: {'booster': 'gblinear', 'learning_rate': 0.09852054716743963, 'max_depth': 8, 'min_child_weight': 2, 'subsample': 0.9130297266898572, 'colsample_bytree': 0.9482994093602386, 'gamma': 1.3382965040833541e-08, 'reg_alpha': 2.2141343055103826e-06, 'reg_lambda': 0.004140250716738102, 'n_estimators': 385, 'scale_pos_weight': 3.4157931556356536, 'max_delta_step': 1.4654238521923555, 'sampling_method': 'gradient_based'}. Best is trial 8 with value: 0.8345546063353166.
[I 2024-02-05 14:28:45,176] Trial 11 finished with value: 0.8202624536125744 and parameters: {'booster': 'gbtree', 'learning_rate': 0.024617289159979235, 'max_depth': 12, 'min_child_weight': 3, 'subsample': 0.9236675997062896, 'colsample_bytree': 0.9183558666784449, 'gamma': 0.01801066237148023, 'reg_alpha': 0.9007503852354171, 'reg_lambda': 0.4431975293465925, 'n_estimators': 299, 'scale_pos_weight': 2.448317711592165, 'max_delta_step': 1.735364136231121, 'sampling_method': 'uniform'}. Best is trial 8 with value: 0.8345546063353166.
[I 2024-02-05 14:28:54,371] Trial 12 finished with value: 0.4130644736205652 and parameters: {'booster': 'gbtree', 'learning_rate': 0.029640383901186274, 'max_depth': 8, 'min_child_weight': 3, 'subsample': 0.8734191462266323, 'colsample_bytree': 0.8792847252195736, 'gamma': 1.4164359534801384e-05, 'reg_alpha': 1.123671972094672e-08, 'reg_lambda': 0.0078007309007569565, 'n_estimators': 251, 'scale_pos_weight': 1.8193716044921726, 'max_delta_step': 0.05047582493032765, 'sampling_method': 'uniform'}. Best is trial 8 with value: 0.8345546063353166.
[I 2024-02-05 14:29:54,916] Trial 13 finished with value: 0.819221973465285 and parameters: {'booster': 'gbtree', 'learning_rate': 0.02287385333995578, 'max_depth': 9, 'min_child_weight': 2, 'subsample': 0.9348878466326256, 'colsample_bytree': 0.9390342821887435, 'gamma': 0.01250781342795408, 'reg_alpha': 5.644121918084005e-07, 'reg_lambda': 3.6257661638289486e-06, 'n_estimators': 294, 'scale_pos_weight': 3.2037786273775417, 'max_delta_step': 1.9816851637265056, 'sampling_method': 'uniform'}. Best is trial 8 with value: 0.8345546063353166.
[I 2024-02-05 14:30:16,687] Trial 14 finished with value: 0.8144076849871592 and parameters: {'booster': 'gbtree', 'learning_rate': 0.04801339273255749, 'max_depth': 8, 'min_child_weight': 3, 'subsample': 0.8882356072450185, 'colsample_bytree': 0.9944050685076629, 'gamma': 0.9300179928462501, 'reg_alpha': 4.5482538187548487e-07, 'reg_lambda': 0.03260814806213902, 'n_estimators': 322, 'scale_pos_weight': 3.0455535444184916, 'max_delta_step': 3.32963385362477, 'sampling_method': 'uniform'}. Best is trial 8 with value: 0.8345546063353166.
[I 2024-02-05 14:40:23,543] Trial 15 finished with value: 0.8222849479341608 and parameters: {'booster': 'dart', 'learning_rate': 0.011690486862005675, 'max_depth': 12, 'min_child_weight': 4, 'subsample': 0.8369650482939248, 'colsample_bytree': 0.8664579812864905, 'gamma': 1.1396636931046825e-05, 'reg_alpha': 4.576348653224304e-06, 'reg_lambda': 0.0003467694957773267, 'n_estimators': 365, 'scale_pos_weight': 1.6137753492528886, 'max_delta_step': 0.8972759380476925, 'sampling_method': 'uniform'}. Best is trial 8 with value: 0.8345546063353166.
[I 2024-02-05 14:41:33,623] Trial 16 finished with value: 0.842681395203868 and parameters: {'booster': 'gbtree', 'learning_rate': 0.07358524209074478, 'max_depth': 11, 'min_child_weight': 2, 'subsample': 0.9538099394289998, 'colsample_bytree': 0.8064770709489739, 'gamma': 0.00020075191000475744, 'reg_alpha': 9.288182845610163e-08, 'reg_lambda': 2.0431846861134896e-07, 'n_estimators': 275, 'scale_pos_weight': 2.807805059567302, 'max_delta_step': 2.1843540459152186, 'sampling_method': 'uniform'}. Best is trial 16 with value: 0.842681395203868.
[I 2024-02-05 14:42:32,809] Trial 17 finished with value: 0.8428512418291968 and parameters: {'booster': 'gbtree', 'learning_rate': 0.09545473505803999, 'max_depth': 11, 'min_child_weight': 2, 'subsample': 0.9555184362997046, 'colsample_bytree': 0.8049128438293065, 'gamma': 0.00021156047759328834, 'reg_alpha': 1.7407293390084688e-07, 'reg_lambda': 3.910029598328329e-07, 'n_estimators': 254, 'scale_pos_weight': 3.792578865210526, 'max_delta_step': 1.8972866271763469, 'sampling_method': 'uniform'}. Best is trial 17 with value: 0.8428512418291968.
[I 2024-02-05 14:42:37,073] Trial 18 finished with value: 0.29208786593919306 and parameters: {'booster': 'gblinear', 'learning_rate': 0.09248499486985645, 'max_depth': 11, 'min_child_weight': 2, 'subsample': 0.9513629729138279, 'colsample_bytree': 0.8110138182535716, 'gamma': 1.5162338324290195e-06, 'reg_alpha': 1.5514240955475637e-07, 'reg_lambda': 1.028492233521704e-08, 'n_estimators': 250, 'scale_pos_weight': 3.919738858238765, 'max_delta_step': 2.0022931793626753, 'sampling_method': 'gradient_based'}. Best is trial 17 with value: 0.8428512418291968.
[I 2024-02-05 14:49:52,367] Trial 19 finished with value: 0.8256687493051873 and parameters: {'booster': 'dart', 'learning_rate': 0.015876804505977015, 'max_depth': 12, 'min_child_weight': 1, 'subsample': 0.9614599283629724, 'colsample_bytree': 0.802541456482574, 'gamma': 0.00025132010654225616, 'reg_alpha': 1.2737723674944403e-07, 'reg_lambda': 2.0313892482500437e-07, 'n_estimators': 268, 'scale_pos_weight': 3.7269172915875406, 'max_delta_step': 2.2402893487823508, 'sampling_method': 'uniform'}. Best is trial 17 with value: 0.8428512418291968.
[I 2024-02-05 14:50:56,417] Trial 20 finished with value: 0.8443242441190344 and parameters: {'booster': 'gbtree', 'learning_rate': 0.07694454010292956, 'max_depth': 11, 'min_child_weight': 2, 'subsample': 0.8973906770812103, 'colsample_bytree': 0.8592261046963797, 'gamma': 0.0029666993159422686, 'reg_alpha': 7.421470037909681e-06, 'reg_lambda': 6.844873569904459e-06, 'n_estimators': 270, 'scale_pos_weight': 4.993585229951632, 'max_delta_step': 3.1863825162745547, 'sampling_method': 'uniform'}. Best is trial 20 with value: 0.8443242441190344.
[I 2024-02-05 14:51:58,875] Trial 21 finished with value: 0.8418738948492229 and parameters: {'booster': 'gbtree', 'learning_rate': 0.08248846593018025, 'max_depth': 11, 'min_child_weight': 2, 'subsample': 0.8978484988171522, 'colsample_bytree': 0.8591596586320137, 'gamma': 0.0038140091089076187, 'reg_alpha': 6.351560779524299e-06, 'reg_lambda': 5.640730084150137e-06, 'n_estimators': 275, 'scale_pos_weight': 4.839409068123216, 'max_delta_step': 3.277626662266313, 'sampling_method': 'uniform'}. Best is trial 20 with value: 0.8443242441190344.
[I 2024-02-05 14:53:08,880] Trial 22 finished with value: 0.8419899481505786 and parameters: {'booster': 'gbtree', 'learning_rate': 0.06578652774991096, 'max_depth': 11, 'min_child_weight': 2, 'subsample': 0.9415440150190781, 'colsample_bytree': 0.803753904840181, 'gamma': 0.00019524780989742732, 'reg_alpha': 1.1226536115765908e-07, 'reg_lambda': 1.1311420801036017e-06, 'n_estimators': 251, 'scale_pos_weight': 3.003490917869582, 'max_delta_step': 3.708291569025503, 'sampling_method': 'uniform'}. Best is trial 20 with value: 0.8443242441190344.
[I 2024-02-05 14:55:14,107] Trial 23 finished with value: 0.8369177813711186 and parameters: {'booster': 'gbtree', 'learning_rate': 0.045984165936618755, 'max_depth': 12, 'min_child_weight': 1, 'subsample': 0.9152399723749723, 'colsample_bytree': 0.8926239426054368, 'gamma': 0.004592675354969189, 'reg_alpha': 1.377903504533614e-06, 'reg_lambda': 1.0759206606374112e-07, 'n_estimators': 299, 'scale_pos_weight': 4.394238594554198, 'max_delta_step': 3.024932189784402, 'sampling_method': 'uniform'}. Best is trial 20 with value: 0.8443242441190344.
[I 2024-02-05 14:57:00,868] Trial 24 finished with value: 0.7997028481453926 and parameters: {'booster': 'gbtree', 'learning_rate': 0.006629921609324222, 'max_depth': 10, 'min_child_weight': 2, 'subsample': 0.884809713842565, 'colsample_bytree': 0.826909999650988, 'gamma': 1.7257178629993373e-05, 'reg_alpha': 7.899670244812608e-08, 'reg_lambda': 0.00012119459747466243, 'n_estimators': 268, 'scale_pos_weight': 3.726900290995358, 'max_delta_step': 1.4891249974375818, 'sampling_method': 'uniform'}. Best is trial 20 with value: 0.8443242441190344.
[I 2024-02-05 14:58:27,326] Trial 25 finished with value: 0.8324000968563053 and parameters: {'booster': 'gbtree', 'learning_rate': 0.03466944796064894, 'max_depth': 11, 'min_child_weight': 3, 'subsample': 0.9695007129117273, 'colsample_bytree': 0.8465601857833486, 'gamma': 0.10834047257433943, 'reg_alpha': 1.2423087733625035e-05, 'reg_lambda': 1.2222029407118563e-05, 'n_estimators': 339, 'scale_pos_weight': 2.793693129329208, 'max_delta_step': 2.4488438008046014, 'sampling_method': 'uniform'}. Best is trial 20 with value: 0.8443242441190344.
[I 2024-02-05 14:59:52,707] Trial 26 finished with value: 0.8480249483398998 and parameters: {'booster': 'gbtree', 'learning_rate': 0.07030063675534776, 'max_depth': 12, 'min_child_weight': 2, 'subsample': 0.9331543586545568, 'colsample_bytree': 0.8183553774832266, 'gamma': 0.004444784013397846, 'reg_alpha': 6.454095539359371e-07, 'reg_lambda': 1.184403938503519e-06, 'n_estimators': 304, 'scale_pos_weight': 3.4697939651126353, 'max_delta_step': 4.85045633660116, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:02:40,720] Trial 27 finished with value: 0.833332426262371 and parameters: {'booster': 'gbtree', 'learning_rate': 0.018418038673620168, 'max_depth': 12, 'min_child_weight': 1, 'subsample': 0.9285183565700386, 'colsample_bytree': 0.8211963511963581, 'gamma': 0.1440475887534838, 'reg_alpha': 0.0003576250477601487, 'reg_lambda': 1.1264720603619645e-06, 'n_estimators': 307, 'scale_pos_weight': 4.9502263778853415, 'max_delta_step': 4.969451434029784, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:08:12,930] Trial 28 finished with value: 0.8451366507496479 and parameters: {'booster': 'dart', 'learning_rate': 0.064926159607069, 'max_depth': 12, 'min_child_weight': 3, 'subsample': 0.905327138185881, 'colsample_bytree': 0.8549745966409577, 'gamma': 0.003924142648653276, 'reg_alpha': 4.79379026114735e-07, 'reg_lambda': 6.239349154722236e-05, 'n_estimators': 288, 'scale_pos_weight': 3.502971412324553, 'max_delta_step': 4.7686585415823695, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:14:31,985] Trial 29 finished with value: 0.833986472173817 and parameters: {'booster': 'dart', 'learning_rate': 0.03772119592444919, 'max_depth': 12, 'min_child_weight': 4, 'subsample': 0.9101717001829995, 'colsample_bytree': 0.888769841294529, 'gamma': 0.0031274701757732257, 'reg_alpha': 5.460927742665471e-07, 'reg_lambda': 7.496398166022305e-05, 'n_estimators': 294, 'scale_pos_weight': 4.493348423446885, 'max_delta_step': 4.777602892606831, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:25:40,112] Trial 30 finished with value: 0.8140898460230971 and parameters: {'booster': 'dart', 'learning_rate': 0.0074610089275699235, 'max_depth': 12, 'min_child_weight': 3, 'subsample': 0.873749220774499, 'colsample_bytree': 0.8608238267144803, 'gamma': 0.005881399507052335, 'reg_alpha': 1.2988685494327263e-05, 'reg_lambda': 0.000528095761405202, 'n_estimators': 364, 'scale_pos_weight': 3.385488728373521, 'max_delta_step': 4.631797444560655, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:31:16,128] Trial 31 finished with value: 0.8440189636161023 and parameters: {'booster': 'dart', 'learning_rate': 0.06935687929658294, 'max_depth': 12, 'min_child_weight': 2, 'subsample': 0.9004081498090833, 'colsample_bytree': 0.8435940432180885, 'gamma': 0.0015104887722308408, 'reg_alpha': 1.9024414314028269e-06, 'reg_lambda': 1.3052565041755804e-05, 'n_estimators': 285, 'scale_pos_weight': 4.051214767136074, 'max_delta_step': 3.968361245120594, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:36:36,085] Trial 32 finished with value: 0.8399250309798202 and parameters: {'booster': 'dart', 'learning_rate': 0.06587670421850625, 'max_depth': 12, 'min_child_weight': 3, 'subsample': 0.9003319615080915, 'colsample_bytree': 0.8465787272406612, 'gamma': 0.001373541435610587, 'reg_alpha': 1.5194895293327106e-06, 'reg_lambda': 8.657329135420136e-06, 'n_estimators': 281, 'scale_pos_weight': 4.019229960573319, 'max_delta_step': 3.9917970539294694, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:42:23,229] Trial 33 finished with value: 0.8362091142714624 and parameters: {'booster': 'dart', 'learning_rate': 0.04305842924552751, 'max_depth': 12, 'min_child_weight': 2, 'subsample': 0.9050514207075316, 'colsample_bytree': 0.8674577449232117, 'gamma': 0.06698505011457395, 'reg_alpha': 0.00023522621448482462, 'reg_lambda': 3.113100582648805e-05, 'n_estimators': 282, 'scale_pos_weight': 4.646866466951492, 'max_delta_step': 3.816426221938198, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:47:53,449] Trial 34 finished with value: 0.8407406646834135 and parameters: {'booster': 'dart', 'learning_rate': 0.06497040212882049, 'max_depth': 12, 'min_child_weight': 3, 'subsample': 0.887205022298247, 'colsample_bytree': 0.8368822213146385, 'gamma': 0.02803496246439332, 'reg_alpha': 1.889162295129239e-05, 'reg_lambda': 0.0001528211081617502, 'n_estimators': 289, 'scale_pos_weight': 3.530056930095566, 'max_delta_step': 4.390359397196143, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:55:01,510] Trial 35 finished with value: 0.8390554651440297 and parameters: {'booster': 'dart', 'learning_rate': 0.028386060447701266, 'max_depth': 11, 'min_child_weight': 1, 'subsample': 0.9233741013357405, 'colsample_bytree': 0.9028762441754299, 'gamma': 0.32152477679368774, 'reg_alpha': 3.113771817193103e-08, 'reg_lambda': 2.8693971134904698e-06, 'n_estimators': 330, 'scale_pos_weight': 4.1224275993146655, 'max_delta_step': 4.9704301262845005, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 15:59:52,815] Trial 36 finished with value: 0.8086966790248539 and parameters: {'booster': 'dart', 'learning_rate': 0.05698428115445309, 'max_depth': 6, 'min_child_weight': 3, 'subsample': 0.9979907372745513, 'colsample_bytree': 0.8213845866167417, 'gamma': 0.01069446571149033, 'reg_alpha': 3.5586129371017358e-06, 'reg_lambda': 5.029911174274285e-05, 'n_estimators': 307, 'scale_pos_weight': 4.646560695624929, 'max_delta_step': 4.099759893464922, 'sampling_method': 'gradient_based'}. Best is trial 26 with value: 0.8480249483398998.
[I 2024-02-05 16:04:15,539] Trial 37 finished with value: 0.8481949391207292 and parameters: {'booster': 'dart', 'learning_rate': 0.07453902064262666, 'max_depth': 10, 'min_child_weight': 2, 'subsample': 0.8701908558054274, 'colsample_bytree': 0.8537562125814606, 'gamma': 0.0014474571445989295, 'reg_alpha': 7.538910828253938e-07, 'reg_lambda': 0.0020156727185691053, 'n_estimators': 262, 'scale_pos_weight': 4.108959910731956, 'max_delta_step': 3.4591065238772583, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:04:19,988] Trial 38 finished with value: 0.16247837423883957 and parameters: {'booster': 'gblinear', 'learning_rate': 0.0032338420773569544, 'max_depth': 10, 'min_child_weight': 4, 'subsample': 0.8638037468099151, 'colsample_bytree': 0.8800118941051261, 'gamma': 0.000519346839485813, 'reg_alpha': 4.846806382844017e-07, 'reg_lambda': 0.018166608330602955, 'n_estimators': 262, 'scale_pos_weight': 3.567977480488503, 'max_delta_step': 2.9959014342982098, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:14:24,983] Trial 39 finished with value: 0.8392863996201649 and parameters: {'booster': 'dart', 'learning_rate': 0.03835551596788681, 'max_depth': 10, 'min_child_weight': 1, 'subsample': 0.8504481330660352, 'colsample_bytree': 0.857110237901397, 'gamma': 0.04028760871255969, 'reg_alpha': 3.4458784160119956e-05, 'reg_lambda': 0.0020818245536157543, 'n_estimators': 407, 'scale_pos_weight': 4.467519266957545, 'max_delta_step': 3.5646047034919044, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:18:54,306] Trial 40 finished with value: 0.8390960244221589 and parameters: {'booster': 'dart', 'learning_rate': 0.051259391242120145, 'max_depth': 10, 'min_child_weight': 3, 'subsample': 0.8764397594022966, 'colsample_bytree': 0.872791848794513, 'gamma': 0.0020180286282970453, 'reg_alpha': 2.926123034813356e-08, 'reg_lambda': 0.14759051793702255, 'n_estimators': 265, 'scale_pos_weight': 4.940828429957337, 'max_delta_step': 4.636180310906868, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:24:09,106] Trial 41 finished with value: 0.8434000678829887 and parameters: {'booster': 'dart', 'learning_rate': 0.0777854284784526, 'max_depth': 11, 'min_child_weight': 2, 'subsample': 0.9007236433435738, 'colsample_bytree': 0.8377617021093023, 'gamma': 0.007746473672239946, 'reg_alpha': 1.0829542424363857e-06, 'reg_lambda': 0.0016180132934970292, 'n_estimators': 285, 'scale_pos_weight': 3.988832665474038, 'max_delta_step': 3.2763972704643054, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:29:21,462] Trial 42 finished with value: 0.8462825248480896 and parameters: {'booster': 'dart', 'learning_rate': 0.05982886872997027, 'max_depth': 11, 'min_child_weight': 2, 'subsample': 0.8912827185684524, 'colsample_bytree': 0.8549612599236472, 'gamma': 0.0006679634987536354, 'reg_alpha': 7.513994590093314e-06, 'reg_lambda': 1.9652271389617858e-05, 'n_estimators': 276, 'scale_pos_weight': 4.174677590189775, 'max_delta_step': 4.222290285828366, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:33:57,511] Trial 43 finished with value: 0.8365314820663522 and parameters: {'booster': 'dart', 'learning_rate': 0.05489790051381994, 'max_depth': 9, 'min_child_weight': 2, 'subsample': 0.892335965537203, 'colsample_bytree': 0.8529395556715884, 'gamma': 0.0006199729112414907, 'reg_alpha': 0.0001453943337902652, 'reg_lambda': 0.0002282357217697129, 'n_estimators': 273, 'scale_pos_weight': 3.2900737545059124, 'max_delta_step': 4.3016544405226345, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:41:24,124] Trial 44 finished with value: 0.7785091918846716 and parameters: {'booster': 'dart', 'learning_rate': 0.0010112163846940326, 'max_depth': 10, 'min_child_weight': 2, 'subsample': 0.8647361046028859, 'colsample_bytree': 0.8882300350575717, 'gamma': 0.0004446412916062318, 'reg_alpha': 7.633971310952077e-06, 'reg_lambda': 2.338533502491424e-05, 'n_estimators': 318, 'scale_pos_weight': 4.298336018247287, 'max_delta_step': 4.589117328294956, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:41:28,835] Trial 45 finished with value: 0.2715215394389004 and parameters: {'booster': 'gblinear', 'learning_rate': 0.09942642699181066, 'max_depth': 11, 'min_child_weight': 2, 'subsample': 0.9427609353156036, 'colsample_bytree': 0.8311132393868897, 'gamma': 4.413426359582361e-05, 'reg_alpha': 3.039294107051135e-07, 'reg_lambda': 0.0011073427990904287, 'n_estimators': 262, 'scale_pos_weight': 4.7031399551968365, 'max_delta_step': 4.17950997047137, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:47:55,832] Trial 46 finished with value: 0.8290129249495751 and parameters: {'booster': 'dart', 'learning_rate': 0.03004073257055556, 'max_depth': 10, 'min_child_weight': 1, 'subsample': 0.8811351016474575, 'colsample_bytree': 0.9182293886677917, 'gamma': 0.0020483062707795812, 'reg_alpha': 3.220319451687685e-05, 'reg_lambda': 6.487367457918511e-05, 'n_estimators': 302, 'scale_pos_weight': 4.2120261555941365, 'max_delta_step': 2.8552466228966624, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:51:56,769] Trial 47 finished with value: 0.8415571889455821 and parameters: {'booster': 'dart', 'learning_rate': 0.08134765132509679, 'max_depth': 11, 'min_child_weight': 5, 'subsample': 0.9181552091106507, 'colsample_bytree': 0.8171826019258149, 'gamma': 0.00010674944850620192, 'reg_alpha': 2.733288697942831e-06, 'reg_lambda': 8.770100336804528e-07, 'n_estimators': 259, 'scale_pos_weight': 2.0727452385784084, 'max_delta_step': 3.5501854869398484, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:53:53,419] Trial 48 finished with value: 0.7922646916720375 and parameters: {'booster': 'gbtree', 'learning_rate': 0.001905772128047016, 'max_depth': 11, 'min_child_weight': 4, 'subsample': 0.8535280358795871, 'colsample_bytree': 0.866799903658818, 'gamma': 0.019786780617708145, 'reg_alpha': 0.032490546837741156, 'reg_lambda': 3.5254756614650466e-06, 'n_estimators': 276, 'scale_pos_weight': 3.636461392990593, 'max_delta_step': 4.743759108829656, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
[I 2024-02-05 16:53:58,164] Trial 49 finished with value: 0.26789627702166485 and parameters: {'booster': 'gblinear', 'learning_rate': 0.0599567599788943, 'max_depth': 9, 'min_child_weight': 3, 'subsample': 0.9316573653108914, 'colsample_bytree': 0.9659990794866411, 'gamma': 0.007160209596019143, 'reg_alpha': 9.353301933173035e-07, 'reg_lambda': 4.0437711308795865e-08, 'n_estimators': 291, 'scale_pos_weight': 0.6705253228412498, 'max_delta_step': 4.498597226971739, 'sampling_method': 'gradient_based'}. Best is trial 37 with value: 0.8481949391207292.
Best Macro F1 Score: 0.8482
Best Parameters:
{'booster': 'dart', 'learning_rate': 0.07453902064262666, 'max_depth': 10, 'min_child_weight': 2, 'subsample': 0.8701908558054274, 'colsample_bytree': 0.8537562125814606, 'gamma': 0.0014474571445989295, 'reg_alpha': 7.538910828253938e-07, 'reg_lambda': 0.0020156727185691053, 'n_estimators': 262, 'scale_pos_weight': 4.108959910731956, 'max_delta_step': 3.4591065238772583, 'sampling_method': 'gradient_based'}
# 0.8292 -> xgb_test_predictions
xgb_params3={'objective': 'multi:softmax', 'eval_metric': 'merror','booster': 'gbtree', 'learning_rate': 0.06640826554255799, 'max_depth': 8, 'min_child_weight': 1,
'subsample': 0.8688162201285817, 'colsample_bytree': 0.9523499834419005, 'gamma': 1.9947806455809915e-05, 'reg_alpha': 0.006244274976595519, 'reg_lambda': 0.0032845719173316035, 'n_estimators': 254,
'tree_method': 'gpu_hist', 'random_state': 42}
# Best Macro F1 Score: 0.8482 -> 최종 제출 후 시도해본 하이퍼파라미터 튜닝
xgb_params={'objective': 'multi:softmax', 'eval_metric': 'merror', 'booster': 'dart', 'learning_rate': 0.07453902064262666, 'max_depth': 10, 'min_child_weight': 2,
'subsample': 0.8701908558054274, 'colsample_bytree': 0.8537562125814606, 'gamma': 0.0014474571445989295, 'reg_alpha': 7.538910828253938e-07, 'reg_lambda': 0.0020156727185691053, 'n_estimators': 262,
'scale_pos_weight': 4.108959910731956, 'max_delta_step': 3.4591065238772583, 'sampling_method': 'gradient_based', 'tree_method': 'gpu_hist', 'random_state': 42}
LGBMClassifier optuna 로 하이퍼파라미터 튜닝:
X_train, X_val, y_train, y_val = train_test_split(loan_total_prepared, loan_labels, test_size=0.1, random_state=42)
def objective(trial: optuna.Trial):
num_classes = len(np.unique(y_train))
lgbm_params = {
'objective': 'multiclass',
'metric': 'multi_logloss',
'num_class': num_classes,
'boosting_type': trial.suggest_categorical('boosting_type', ['gbdt', 'rf', 'dart']),
'num_leaves': trial.suggest_int('num_leaves', 10, 50),
'learning_rate': trial.suggest_loguniform('learning_rate', 0.0001, 0.1),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.7, 1.0),
'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.7, 1.0),
'bagging_freq': trial.suggest_int('bagging_freq', 1, 15),
'min_child_samples': trial.suggest_int('min_child_samples', 10, 50),
'n_estimators': trial.suggest_int('n_estimators', 300, 800),
'max_depth': trial.suggest_int('max_depth', 5, 15),
'min_child_weight': trial.suggest_loguniform('min_child_weight', 1e-8, 1.0),
'subsample': trial.suggest_uniform('subsample', 0.7, 1.0),
'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.7, 1.0),
'reg_alpha': trial.suggest_loguniform('reg_alpha', 1e-8, 1.0),
'reg_lambda': trial.suggest_loguniform('reg_lambda', 1e-8, 1.0),
'gamma': trial.suggest_loguniform('gamma', 1e-8, 1.0),
'min_split_gain': trial.suggest_loguniform('min_split_gain', 1e-8, 1.0),
'subsample_freq': trial.suggest_int('subsample_freq', 1, 15),
'colsample_bylevel': trial.suggest_uniform('colsample_bylevel', 0.5, 1.0),
'max_bin': trial.suggest_int('max_bin', 100, 255),
'scale_pos_weight': trial.suggest_loguniform('scale_pos_weight', 1e-8, 1.0),
'device': 'gpu',
'random_state': 42
}
model = lgb.LGBMClassifier(**lgbm_params, verbose=-1)
model.fit(X_train, y_train, eval_set=[(X_val, y_val)], callbacks=[lgb.early_stopping(100, verbose=False)])
y_pred = model.predict(X_val)
macro_f1 = f1_score(y_val, y_pred, average='macro')
return macro_f1
def optimize_lgbm():
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=30)
if study.best_trial is not None:
best_params = study.best_params
best_macro_f1 = study.best_value
print(f"Best Macro F1 Score: {best_macro_f1:.4f}")
print("Best Parameters:")
print(best_params)
else:
print("No completed trials.")
optimize_lgbm()
[I 2024-02-05 18:03:25,294] A new study created in memory with name: no-name-0c016c3b-e448-4a9c-be29-d121281254f5
[I 2024-02-05 18:04:49,787] Trial 0 finished with value: 0.6806338577817515 and parameters: {'boosting_type': 'dart', 'num_leaves': 33, 'learning_rate': 0.0033843601903895816, 'feature_fraction': 0.7877568745019989, 'bagging_fraction': 0.7755627265768992, 'bagging_freq': 15, 'min_child_samples': 22, 'n_estimators': 550, 'max_depth': 7, 'min_child_weight': 2.513749259869577e-07, 'subsample': 0.8465347383491029, 'colsample_bytree': 0.9025513285714193, 'reg_alpha': 0.043605498542124387, 'reg_lambda': 5.1649386380311114e-05, 'gamma': 0.004137403508542368, 'min_split_gain': 0.002053950621164617, 'subsample_freq': 9, 'colsample_bylevel': 0.8690392897198818, 'max_bin': 197, 'scale_pos_weight': 1.4982888495011528e-07}. Best is trial 0 with value: 0.6806338577817515.
[I 2024-02-05 18:05:24,664] Trial 1 finished with value: 0.1546037946069945 and parameters: {'boosting_type': 'dart', 'num_leaves': 17, 'learning_rate': 0.0001190814131070538, 'feature_fraction': 0.9248470763089649, 'bagging_fraction': 0.9483657841233872, 'bagging_freq': 3, 'min_child_samples': 32, 'n_estimators': 380, 'max_depth': 12, 'min_child_weight': 1.4757590481632619e-05, 'subsample': 0.8923306118836518, 'colsample_bytree': 0.9760858505174229, 'reg_alpha': 1.2596511179475325e-05, 'reg_lambda': 0.09901269211021893, 'gamma': 2.7244795859898863e-08, 'min_split_gain': 4.219222546478415e-05, 'subsample_freq': 8, 'colsample_bylevel': 0.9502534740877016, 'max_bin': 157, 'scale_pos_weight': 1.7111194594759036e-08}. Best is trial 0 with value: 0.6806338577817515.
[I 2024-02-05 18:05:55,033] Trial 2 finished with value: 0.753657918015063 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 40, 'learning_rate': 0.009919164232847225, 'feature_fraction': 0.7528455027125172, 'bagging_fraction': 0.7204900512853228, 'bagging_freq': 15, 'min_child_samples': 12, 'n_estimators': 660, 'max_depth': 5, 'min_child_weight': 7.552539055794802e-08, 'subsample': 0.8326975768870851, 'colsample_bytree': 0.7723315467479395, 'reg_alpha': 0.10450860259198741, 'reg_lambda': 7.253454150011686e-08, 'gamma': 0.0020497194792168014, 'min_split_gain': 0.08295775141585746, 'subsample_freq': 8, 'colsample_bylevel': 0.962740891815906, 'max_bin': 101, 'scale_pos_weight': 0.00016715639591019925}. Best is trial 2 with value: 0.753657918015063.
[I 2024-02-05 18:07:06,986] Trial 3 finished with value: 0.7598592480929122 and parameters: {'boosting_type': 'dart', 'num_leaves': 45, 'learning_rate': 0.015041704961027271, 'feature_fraction': 0.8764724511431439, 'bagging_fraction': 0.7088978355168262, 'bagging_freq': 7, 'min_child_samples': 21, 'n_estimators': 412, 'max_depth': 13, 'min_child_weight': 7.226289932146811e-08, 'subsample': 0.9453737032723198, 'colsample_bytree': 0.9196893392949171, 'reg_alpha': 2.264543638780695e-05, 'reg_lambda': 3.7567638466477732e-06, 'gamma': 1.1649843137863254e-08, 'min_split_gain': 1.8540550424532873e-06, 'subsample_freq': 1, 'colsample_bylevel': 0.6250452287498811, 'max_bin': 187, 'scale_pos_weight': 7.041717991126363e-08}. Best is trial 3 with value: 0.7598592480929122.
[I 2024-02-05 18:07:51,110] Trial 4 finished with value: 0.797175578603502 and parameters: {'boosting_type': 'dart', 'num_leaves': 24, 'learning_rate': 0.09547232587362256, 'feature_fraction': 0.9456449606508782, 'bagging_fraction': 0.8181830062445626, 'bagging_freq': 6, 'min_child_samples': 31, 'n_estimators': 369, 'max_depth': 8, 'min_child_weight': 0.720613218538633, 'subsample': 0.8147997553777555, 'colsample_bytree': 0.8652538621650272, 'reg_alpha': 1.541385641888406e-08, 'reg_lambda': 4.457579279480872e-06, 'gamma': 0.18163643829858978, 'min_split_gain': 0.03226707121448687, 'subsample_freq': 10, 'colsample_bylevel': 0.8976292445870133, 'max_bin': 205, 'scale_pos_weight': 7.01445981071613e-07}. Best is trial 4 with value: 0.797175578603502.
[I 2024-02-05 18:08:20,377] Trial 5 finished with value: 0.4925821354861574 and parameters: {'boosting_type': 'dart', 'num_leaves': 11, 'learning_rate': 0.003956322521477891, 'feature_fraction': 0.7461420385815964, 'bagging_fraction': 0.7981679761393674, 'bagging_freq': 5, 'min_child_samples': 16, 'n_estimators': 397, 'max_depth': 11, 'min_child_weight': 5.3022192004731074e-08, 'subsample': 0.7859698743624018, 'colsample_bytree': 0.8885140869293527, 'reg_alpha': 0.003317888899093067, 'reg_lambda': 1.7013172765112974e-06, 'gamma': 8.26672139485385e-06, 'min_split_gain': 8.67661806536222e-06, 'subsample_freq': 10, 'colsample_bylevel': 0.9099209068427743, 'max_bin': 172, 'scale_pos_weight': 1.5072918976073627e-06}. Best is trial 4 with value: 0.797175578603502.
[I 2024-02-05 18:09:03,082] Trial 6 finished with value: 0.7927928465279303 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 33, 'learning_rate': 0.006841962857020719, 'feature_fraction': 0.9774692278873096, 'bagging_fraction': 0.702369271531852, 'bagging_freq': 8, 'min_child_samples': 16, 'n_estimators': 701, 'max_depth': 12, 'min_child_weight': 5.637272079518773e-08, 'subsample': 0.7524804642968557, 'colsample_bytree': 0.8301497501605137, 'reg_alpha': 5.118542292413463e-06, 'reg_lambda': 1.919008542412795e-06, 'gamma': 0.056283639267207586, 'min_split_gain': 0.776981397203604, 'subsample_freq': 13, 'colsample_bylevel': 0.931521900198014, 'max_bin': 239, 'scale_pos_weight': 0.0021956662935348225}. Best is trial 4 with value: 0.797175578603502.
[I 2024-02-05 18:09:57,498] Trial 7 finished with value: 0.7005359876041198 and parameters: {'boosting_type': 'dart', 'num_leaves': 22, 'learning_rate': 0.02701638136924943, 'feature_fraction': 0.8734847184926815, 'bagging_fraction': 0.8646929260286336, 'bagging_freq': 10, 'min_child_samples': 39, 'n_estimators': 481, 'max_depth': 5, 'min_child_weight': 0.00047078565343710666, 'subsample': 0.7672245895398088, 'colsample_bytree': 0.9924324007906704, 'reg_alpha': 7.817726846652037e-05, 'reg_lambda': 1.5583667283602852e-08, 'gamma': 0.00016740907629459413, 'min_split_gain': 0.392379361964818, 'subsample_freq': 12, 'colsample_bylevel': 0.9934343622287842, 'max_bin': 216, 'scale_pos_weight': 2.9978497159610355e-05}. Best is trial 4 with value: 0.797175578603502.
[I 2024-02-05 18:10:44,789] Trial 8 finished with value: 0.7347046098360427 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 44, 'learning_rate': 0.0016298676221743987, 'feature_fraction': 0.7613395275005777, 'bagging_fraction': 0.9089385065130592, 'bagging_freq': 11, 'min_child_samples': 27, 'n_estimators': 564, 'max_depth': 13, 'min_child_weight': 0.0002732558470131327, 'subsample': 0.7573795188165777, 'colsample_bytree': 0.722681964698131, 'reg_alpha': 5.7833540899175297e-05, 'reg_lambda': 2.376007327464573e-05, 'gamma': 5.8469015045687276e-05, 'min_split_gain': 5.926618102720292e-07, 'subsample_freq': 5, 'colsample_bylevel': 0.7992146905717008, 'max_bin': 233, 'scale_pos_weight': 5.26310828689461e-06}. Best is trial 4 with value: 0.797175578603502.
[I 2024-02-05 18:11:14,577] Trial 9 finished with value: 0.7067137108059398 and parameters: {'boosting_type': 'dart', 'num_leaves': 27, 'learning_rate': 0.0067376809241848435, 'feature_fraction': 0.9180516670730081, 'bagging_fraction': 0.9533626900747016, 'bagging_freq': 6, 'min_child_samples': 27, 'n_estimators': 309, 'max_depth': 12, 'min_child_weight': 0.00019724242558712387, 'subsample': 0.8919930787850139, 'colsample_bytree': 0.913985757497983, 'reg_alpha': 6.831957113567079e-05, 'reg_lambda': 2.6260637846499043e-06, 'gamma': 0.13029445290499825, 'min_split_gain': 3.0401151609535387e-06, 'subsample_freq': 9, 'colsample_bylevel': 0.5591122823975359, 'max_bin': 212, 'scale_pos_weight': 3.1164498383346525e-07}. Best is trial 4 with value: 0.797175578603502.
[I 2024-02-05 18:11:20,680] Trial 10 finished with value: 0.578391834307511 and parameters: {'boosting_type': 'rf', 'num_leaves': 22, 'learning_rate': 0.09479853352205114, 'feature_fraction': 0.9981628585294043, 'bagging_fraction': 0.8255627771353282, 'bagging_freq': 2, 'min_child_samples': 47, 'n_estimators': 798, 'max_depth': 9, 'min_child_weight': 0.6661308428290047, 'subsample': 0.7128185950302449, 'colsample_bytree': 0.8266092478727097, 'reg_alpha': 1.4296387902603292e-08, 'reg_lambda': 0.011472876330804167, 'gamma': 0.5506833495752121, 'min_split_gain': 0.0024709042095794756, 'subsample_freq': 15, 'colsample_bylevel': 0.7129428335608015, 'max_bin': 138, 'scale_pos_weight': 0.016793144798360776}. Best is trial 4 with value: 0.797175578603502.
[I 2024-02-05 18:12:04,170] Trial 11 finished with value: 0.5045891498592417 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 34, 'learning_rate': 0.0005018689990543405, 'feature_fraction': 0.9898139511475947, 'bagging_fraction': 0.7557424647559965, 'bagging_freq': 9, 'min_child_samples': 35, 'n_estimators': 710, 'max_depth': 15, 'min_child_weight': 0.7625604852816825, 'subsample': 0.7133160036964439, 'colsample_bytree': 0.8308421870320851, 'reg_alpha': 2.8908149555544245e-08, 'reg_lambda': 0.0014799096094366506, 'gamma': 0.037947078289846795, 'min_split_gain': 1.6400342083462247e-08, 'subsample_freq': 14, 'colsample_bylevel': 0.8272032174060434, 'max_bin': 247, 'scale_pos_weight': 0.00234417824342208}. Best is trial 4 with value: 0.797175578603502.
[I 2024-02-05 18:12:16,693] Trial 12 finished with value: 0.6280874265904716 and parameters: {'boosting_type': 'rf', 'num_leaves': 29, 'learning_rate': 0.08659313859169304, 'feature_fraction': 0.9471797439876017, 'bagging_fraction': 0.8623405993089617, 'bagging_freq': 12, 'min_child_samples': 41, 'n_estimators': 648, 'max_depth': 9, 'min_child_weight': 0.01392141701866032, 'subsample': 0.8010794660442919, 'colsample_bytree': 0.7840083130894744, 'reg_alpha': 6.647879106985769e-07, 'reg_lambda': 1.8350243210959238e-07, 'gamma': 0.7457747403300327, 'min_split_gain': 0.025377540090881882, 'subsample_freq': 12, 'colsample_bylevel': 0.7311115809553898, 'max_bin': 248, 'scale_pos_weight': 0.4830971669182727}. Best is trial 4 with value: 0.797175578603502.
[I 2024-02-05 18:12:41,740] Trial 13 finished with value: 0.8065276484423883 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 38, 'learning_rate': 0.0328178241528492, 'feature_fraction': 0.8168615536064087, 'bagging_fraction': 0.997421629429196, 'bagging_freq': 4, 'min_child_samples': 11, 'n_estimators': 775, 'max_depth': 8, 'min_child_weight': 3.646293070827056e-06, 'subsample': 0.9765349467302982, 'colsample_bytree': 0.8599525781788036, 'reg_alpha': 5.104133100400787e-07, 'reg_lambda': 0.0004924067731326195, 'gamma': 0.00683055878587334, 'min_split_gain': 0.8278330209149006, 'subsample_freq': 5, 'colsample_bylevel': 0.8803101485267955, 'max_bin': 223, 'scale_pos_weight': 0.0007562769296337485}. Best is trial 13 with value: 0.8065276484423883.
[I 2024-02-05 18:13:38,884] Trial 14 finished with value: 0.8275445532411146 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 50, 'learning_rate': 0.02911574162724357, 'feature_fraction': 0.81435378426325, 'bagging_fraction': 0.8895268575162475, 'bagging_freq': 4, 'min_child_samples': 23, 'n_estimators': 787, 'max_depth': 7, 'min_child_weight': 3.699757478264858e-06, 'subsample': 0.9942550680472569, 'colsample_bytree': 0.8835185973996887, 'reg_alpha': 1.4109064666691135e-07, 'reg_lambda': 0.0005894793892358044, 'gamma': 0.002095736370386335, 'min_split_gain': 0.003218461391974306, 'subsample_freq': 5, 'colsample_bylevel': 0.8539607851138615, 'max_bin': 214, 'scale_pos_weight': 0.00010584941375673745}. Best is trial 14 with value: 0.8275445532411146.
[I 2024-02-05 18:14:38,306] Trial 15 finished with value: 0.8216735234633619 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 50, 'learning_rate': 0.02774119973654347, 'feature_fraction': 0.817721609080817, 'bagging_fraction': 0.9799365561443042, 'bagging_freq': 4, 'min_child_samples': 13, 'n_estimators': 788, 'max_depth': 7, 'min_child_weight': 4.398286062855663e-06, 'subsample': 0.9961069272976132, 'colsample_bytree': 0.9577476792419265, 'reg_alpha': 4.0107505077839785e-07, 'reg_lambda': 0.000787106502405848, 'gamma': 0.00239390508823993, 'min_split_gain': 0.0009796594198125, 'subsample_freq': 4, 'colsample_bylevel': 0.7898126905926247, 'max_bin': 223, 'scale_pos_weight': 0.00020861371660723662}. Best is trial 14 with value: 0.8275445532411146.
[I 2024-02-05 18:15:29,003] Trial 16 finished with value: 0.8177000920686309 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 49, 'learning_rate': 0.03027889129721372, 'feature_fraction': 0.7064375844624522, 'bagging_fraction': 0.9127267226022738, 'bagging_freq': 1, 'min_child_samples': 21, 'n_estimators': 733, 'max_depth': 7, 'min_child_weight': 1.313638997697558e-06, 'subsample': 0.9959751524493898, 'colsample_bytree': 0.9556970955781359, 'reg_alpha': 3.144327880918534e-07, 'reg_lambda': 0.006034742075666534, 'gamma': 2.635084388892681e-06, 'min_split_gain': 0.0007953157363445753, 'subsample_freq': 3, 'colsample_bylevel': 0.6696272259844126, 'max_bin': 176, 'scale_pos_weight': 2.8837091952016722e-05}. Best is trial 14 with value: 0.8275445532411146.
[I 2024-02-05 18:16:12,147] Trial 17 finished with value: 0.6210335238579044 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 45, 'learning_rate': 0.0011742479921686775, 'feature_fraction': 0.8291680333060096, 'bagging_fraction': 0.9875828275177607, 'bagging_freq': 3, 'min_child_samples': 16, 'n_estimators': 606, 'max_depth': 6, 'min_child_weight': 1.1394456964537625e-05, 'subsample': 0.9391311431788647, 'colsample_bytree': 0.9463804094683573, 'reg_alpha': 0.0018938994576246657, 'reg_lambda': 0.4008960163080693, 'gamma': 0.00030753622315885876, 'min_split_gain': 0.00019563675654734857, 'subsample_freq': 5, 'colsample_bylevel': 0.797132835649335, 'max_bin': 255, 'scale_pos_weight': 0.03867779193748994}. Best is trial 14 with value: 0.8275445532411146.
[I 2024-02-05 18:17:17,310] Trial 18 finished with value: 0.8239823739181642 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 50, 'learning_rate': 0.042230975914390664, 'feature_fraction': 0.8600466822372178, 'bagging_fraction': 0.894611056151271, 'bagging_freq': 4, 'min_child_samples': 25, 'n_estimators': 758, 'max_depth': 10, 'min_child_weight': 0.0033157052554342588, 'subsample': 0.9001430186963169, 'colsample_bytree': 0.9427686444017053, 'reg_alpha': 1.3933440023529232e-07, 'reg_lambda': 0.0003315680431259724, 'gamma': 0.000947049155283305, 'min_split_gain': 0.006985313745228661, 'subsample_freq': 3, 'colsample_bylevel': 0.5045964540270196, 'max_bin': 198, 'scale_pos_weight': 0.0002712540251897064}. Best is trial 14 with value: 0.8275445532411146.
[I 2024-02-05 18:17:27,233] Trial 19 finished with value: 0.6661446365651792 and parameters: {'boosting_type': 'rf', 'num_leaves': 38, 'learning_rate': 0.04915990572774035, 'feature_fraction': 0.8608631082175711, 'bagging_fraction': 0.9017725701183102, 'bagging_freq': 1, 'min_child_samples': 25, 'n_estimators': 736, 'max_depth': 10, 'min_child_weight': 0.0045887015670234696, 'subsample': 0.887545196201466, 'colsample_bytree': 0.9286070277230332, 'reg_alpha': 0.0007700293287521504, 'reg_lambda': 0.0001442125149294012, 'gamma': 7.178499304302596e-07, 'min_split_gain': 0.010259167647472558, 'subsample_freq': 1, 'colsample_bylevel': 0.5126982027469272, 'max_bin': 149, 'scale_pos_weight': 1.2080370034038749e-05}. Best is trial 14 with value: 0.8275445532411146.
[I 2024-02-05 18:18:26,132] Trial 20 finished with value: 0.8157383434654941 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 50, 'learning_rate': 0.018071205075704547, 'feature_fraction': 0.7841969558852038, 'bagging_fraction': 0.8881723715317579, 'bagging_freq': 5, 'min_child_samples': 36, 'n_estimators': 666, 'max_depth': 10, 'min_child_weight': 0.026621539024449026, 'subsample': 0.9228797772098207, 'colsample_bytree': 0.8878355501231354, 'reg_alpha': 7.380653534443125e-08, 'reg_lambda': 0.018847289460712516, 'gamma': 3.3043397691136765e-05, 'min_split_gain': 6.899441533820705e-05, 'subsample_freq': 3, 'colsample_bylevel': 0.6146709591791578, 'max_bin': 191, 'scale_pos_weight': 0.02653195193900972}. Best is trial 14 with value: 0.8275445532411146.
[I 2024-02-05 18:19:25,630] Trial 21 finished with value: 0.8249315349864091 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 50, 'learning_rate': 0.04739175395431141, 'feature_fraction': 0.8306057971509478, 'bagging_fraction': 0.9463641346504764, 'bagging_freq': 4, 'min_child_samples': 20, 'n_estimators': 800, 'max_depth': 7, 'min_child_weight': 0.0019641795546000264, 'subsample': 0.9725377154970596, 'colsample_bytree': 0.9582279236016977, 'reg_alpha': 2.6995368223732918e-06, 'reg_lambda': 0.0010135738630757897, 'gamma': 0.0007215005879892404, 'min_split_gain': 0.003416944090933043, 'subsample_freq': 3, 'colsample_bylevel': 0.7666974745252843, 'max_bin': 225, 'scale_pos_weight': 0.00043375156682060376}. Best is trial 14 with value: 0.8275445532411146.
[I 2024-02-05 18:20:10,392] Trial 22 finished with value: 0.8281391274655437 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 43, 'learning_rate': 0.05601207066571805, 'feature_fraction': 0.8855038934711994, 'bagging_fraction': 0.9369042030247965, 'bagging_freq': 4, 'min_child_samples': 24, 'n_estimators': 754, 'max_depth': 6, 'min_child_weight': 0.0030506830620800097, 'subsample': 0.9630017515968321, 'colsample_bytree': 0.9382226354744757, 'reg_alpha': 3.5074606227723373e-06, 'reg_lambda': 0.00022423464697137542, 'gamma': 0.0006615186930042856, 'min_split_gain': 0.006227762335834626, 'subsample_freq': 6, 'colsample_bylevel': 0.6819222661103538, 'max_bin': 204, 'scale_pos_weight': 0.0005352542621407072}. Best is trial 22 with value: 0.8281391274655437.
[I 2024-02-05 18:20:54,934] Trial 23 finished with value: 0.8357126617743978 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 43, 'learning_rate': 0.05518263792327762, 'feature_fraction': 0.9005235878266725, 'bagging_fraction': 0.9426591509615256, 'bagging_freq': 7, 'min_child_samples': 20, 'n_estimators': 799, 'max_depth': 6, 'min_child_weight': 4.554432495565188e-05, 'subsample': 0.9658125356057697, 'colsample_bytree': 0.9838255892694429, 'reg_alpha': 2.794537316222453e-06, 'reg_lambda': 0.0026299417628385786, 'gamma': 0.01497172077910722, 'min_split_gain': 0.0002708153701172625, 'subsample_freq': 6, 'colsample_bylevel': 0.6928739842983858, 'max_bin': 227, 'scale_pos_weight': 0.0026557786558643226}. Best is trial 23 with value: 0.8357126617743978.
[I 2024-02-05 18:21:39,012] Trial 24 finished with value: 0.7999705419992024 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 41, 'learning_rate': 0.01468355803838562, 'feature_fraction': 0.8894610817769503, 'bagging_fraction': 0.9289185806994107, 'bagging_freq': 7, 'min_child_samples': 18, 'n_estimators': 705, 'max_depth': 6, 'min_child_weight': 5.91879402367187e-05, 'subsample': 0.9619139426749136, 'colsample_bytree': 0.995591439391105, 'reg_alpha': 2.4532312928102506e-06, 'reg_lambda': 0.0027528008329686764, 'gamma': 0.018401929205978218, 'min_split_gain': 0.00032153791571358585, 'subsample_freq': 6, 'colsample_bylevel': 0.6891206428373651, 'max_bin': 210, 'scale_pos_weight': 0.0059045506963492055}. Best is trial 23 with value: 0.8357126617743978.
[I 2024-02-05 18:22:18,007] Trial 25 finished with value: 0.8309212795981883 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 46, 'learning_rate': 0.0588463584643865, 'feature_fraction': 0.9017536100441881, 'bagging_fraction': 0.9671280791083666, 'bagging_freq': 8, 'min_child_samples': 24, 'n_estimators': 743, 'max_depth': 6, 'min_child_weight': 7.012949974533018e-05, 'subsample': 0.9189070541078642, 'colsample_bytree': 0.8889575961549874, 'reg_alpha': 0.0003488520786974781, 'reg_lambda': 0.051945304529932956, 'gamma': 0.009967788914755395, 'min_split_gain': 0.10615296814059756, 'subsample_freq': 6, 'colsample_bylevel': 0.6275556663244045, 'max_bin': 234, 'scale_pos_weight': 0.20021801034663672}. Best is trial 23 with value: 0.8357126617743978.
[I 2024-02-05 18:22:27,506] Trial 26 finished with value: 0.5240527888712911 and parameters: {'boosting_type': 'rf', 'num_leaves': 42, 'learning_rate': 0.06006380403574349, 'feature_fraction': 0.9036644972454856, 'bagging_fraction': 0.9605891561685213, 'bagging_freq': 8, 'min_child_samples': 29, 'n_estimators': 594, 'max_depth': 5, 'min_child_weight': 4.198129841616286e-05, 'subsample': 0.9148423103990253, 'colsample_bytree': 0.9712308834812261, 'reg_alpha': 0.0004708976950382631, 'reg_lambda': 0.05642269414466476, 'gamma': 0.013127232364595854, 'min_split_gain': 0.14822022441624486, 'subsample_freq': 7, 'colsample_bylevel': 0.639618103944719, 'max_bin': 236, 'scale_pos_weight': 0.2421661419634549}. Best is trial 23 with value: 0.8357126617743978.
[I 2024-02-05 18:23:01,825] Trial 27 finished with value: 0.8295334402083572 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 36, 'learning_rate': 0.060641005408778016, 'feature_fraction': 0.9563744105161153, 'bagging_fraction': 0.9720364228188482, 'bagging_freq': 9, 'min_child_samples': 28, 'n_estimators': 683, 'max_depth': 6, 'min_child_weight': 0.10225206007914568, 'subsample': 0.9467420987518883, 'colsample_bytree': 0.9255179854701602, 'reg_alpha': 0.013601644593091742, 'reg_lambda': 0.5962351811200223, 'gamma': 0.00032005929409097253, 'min_split_gain': 0.07017773593255004, 'subsample_freq': 7, 'colsample_bylevel': 0.5796029041385726, 'max_bin': 232, 'scale_pos_weight': 0.15204664492936473}. Best is trial 23 with value: 0.8357126617743978.
[I 2024-02-05 18:23:41,809] Trial 28 finished with value: 0.17887273193170403 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 35, 'learning_rate': 0.0001995828897340164, 'feature_fraction': 0.9536404833646184, 'bagging_fraction': 0.9714402690839415, 'bagging_freq': 13, 'min_child_samples': 34, 'n_estimators': 627, 'max_depth': 8, 'min_child_weight': 0.12191690376840002, 'subsample': 0.8684451565001056, 'colsample_bytree': 0.9043149997284573, 'reg_alpha': 0.015682418298352912, 'reg_lambda': 0.9955815425612691, 'gamma': 1.4768268434790883e-05, 'min_split_gain': 0.10692285893504251, 'subsample_freq': 7, 'colsample_bylevel': 0.5705627926137047, 'max_bin': 237, 'scale_pos_weight': 0.1451620912069224}. Best is trial 23 with value: 0.8357126617743978.
[I 2024-02-05 18:24:11,059] Trial 29 finished with value: 0.7243161448257306 and parameters: {'boosting_type': 'gbdt', 'num_leaves': 36, 'learning_rate': 0.003077021262474917, 'feature_fraction': 0.9674026913524683, 'bagging_fraction': 0.9998531174601368, 'bagging_freq': 10, 'min_child_samples': 29, 'n_estimators': 511, 'max_depth': 6, 'min_child_weight': 5.673894661232022e-07, 'subsample': 0.8642394721714328, 'colsample_bytree': 0.9791373526858314, 'reg_alpha': 0.6614538945920048, 'reg_lambda': 0.158353002384168, 'gamma': 0.006364679466209971, 'min_split_gain': 5.8542543168520176e-08, 'subsample_freq': 9, 'colsample_bylevel': 0.5753394056297655, 'max_bin': 122, 'scale_pos_weight': 0.7497371350671591}. Best is trial 23 with value: 0.8357126617743978.
Best Macro F1 Score: 0.8357
Best Parameters:
{'boosting_type': 'gbdt', 'num_leaves': 43, 'learning_rate': 0.05518263792327762, 'feature_fraction': 0.9005235878266725, 'bagging_fraction': 0.9426591509615256, 'bagging_freq': 7, 'min_child_samples': 20, 'n_estimators': 799, 'max_depth': 6, 'min_child_weight': 4.554432495565188e-05, 'subsample': 0.9658125356057697, 'colsample_bytree': 0.9838255892694429, 'reg_alpha': 2.794537316222453e-06, 'reg_lambda': 0.0026299417628385786, 'gamma': 0.01497172077910722, 'min_split_gain': 0.0002708153701172625, 'subsample_freq': 6, 'colsample_bylevel': 0.6928739842983858, 'max_bin': 227, 'scale_pos_weight': 0.0026557786558643226}
# lgbm_test_predictions
lgbm_params1={'objective': 'multiclass', 'metric': 'multi_logloss','boosting_type': 'gbdt', 'num_leaves': 73, 'learning_rate': 0.07228116939428798, 'feature_fraction': 0.9430109139466885,
'bagging_fraction': 0.9815972577904344, 'bagging_freq': 10, 'min_child_samples': 9, 'n_estimators': 436, 'max_depth': 8, 'min_child_weight': 0.002774335258628078, 'subsample': 0.7937163862883831,
'colsample_bytree': 0.8784969823144121, 'reg_alpha': 7.008352155732409e-06, 'reg_lambda': 0.019141374287422526, 'gamma': 0.003215189372648936, 'min_split_gain': 0.00047588264679936733,
'subsample_freq': 7, 'colsample_bylevel': 0.8731399738662942, 'max_bin': 202, 'scale_pos_weight': 6.595555117581444e-07, 'device': 'gpu', 'random_state': 42}
테스트 데이터 예측
테스트 데이터로 예측:
test_prepared = full_pipeline.transform(test)
test_total_prepared=test_prepared[:, [ 0, 5, 6, 20, 23]] # 최상위 5개 특성만 추출
test_total_prepared.shape
(64197, 5)
def k_fold_cross_validation(X, y, k, model, params, test):
skf = StratifiedKFold(n_splits=k, shuffle=True, random_state=42)
macro_f1_scores = []
final_predictions = []
for train_idx, val_idx in tqdm(skf.split(X, y), total=k, desc='Cross Validation Progress'):
X_train, X_val = X[train_idx], X[val_idx]
y_train, y_val = y[train_idx], y[val_idx]
model_instance = model(**params)
model_instance.fit(X_train, y_train, eval_set=[(X_val, y_val)], early_stopping_rounds=50, verbose=False)
val_predictions = model_instance.predict(X_val)
macro_f1 = f1_score(y_val, val_predictions, average='macro')
macro_f1_scores.append(macro_f1)
xgb_predictions = model_instance.predict_proba(test)
final_predictions.append(xgb_predictions)
mean_macro_f1 = np.mean(macro_f1_scores)
return mean_macro_f1, final_predictions
XGBClassifier CV 10회 점수 평균 및 test 예측:
# Mean Macro F1 Score: 0.8276
xgb_params3={'objective': 'multi:softmax', 'eval_metric': 'merror','booster': 'gbtree', 'learning_rate': 0.06640826554255799, 'max_depth': 8, 'min_child_weight': 1,
'subsample': 0.8688162201285817, 'colsample_bytree': 0.9523499834419005, 'gamma': 1.9947806455809915e-05, 'reg_alpha': 0.006244274976595519, 'reg_lambda': 0.0032845719173316035, 'n_estimators': 254,
'tree_method': 'gpu_hist', 'random_state': 42}
k = 10
xgb_mean_macro_f1, xgb_test_predictions = k_fold_cross_validation(loan_total_prepared, loan_labels, k, XGBClassifier, xgb_params3, test_total_prepared)
print(f"Mean Macro F1 Score: {xgb_mean_macro_f1:.4f}")
print("Mean Test Predictions:")
print(xgb_test_predictions)
Cross Validation Progress: 100%|███████████████████████████████████████████████████████| 10/10 [05:06<00:00, 30.64s/it]
Mean Macro F1 Score: 0.8276
Mean Test Predictions:
[array([[2.70498767e-02, 7.16049790e-01, 2.46456906e-01, ...,
1.25093525e-03, 1.63567660e-04, 7.90776685e-05],
[1.81007057e-01, 3.90339553e-01, 2.92833418e-01, ...,
2.37505920e-02, 8.98073800e-03, 8.53021105e-04],
[9.72842097e-01, 2.32564677e-02, 3.34605854e-03, ...,
7.93401850e-05, 3.29237992e-05, 1.58580515e-05],
...,
[1.19078544e-03, 1.89830568e-02, 7.61869922e-02, ...,
1.16622865e-01, 1.49928930e-03, 1.68705606e-04],
[1.73923897e-03, 1.20664835e-02, 9.60608959e-01, ...,
3.59332305e-03, 7.03082711e-04, 3.01224558e-04],
[9.80742097e-01, 1.55147379e-02, 2.75464635e-03, ...,
5.74539008e-05, 2.99442781e-05, 1.40648008e-05]], dtype=float32), array([[2.51692533e-02, 8.27670634e-01, 1.36210144e-01, ...,
1.34744775e-03, 1.11104084e-04, 5.79088628e-05],
[1.90954030e-01, 3.91270459e-01, 2.74654120e-01, ...,
3.30666341e-02, 8.80888104e-03, 4.39648749e-04],
[9.72406566e-01, 2.48448197e-02, 2.34369282e-03, ...,
8.95756093e-05, 2.33242245e-05, 1.08816366e-05],
...,
[1.00513746e-03, 2.30701026e-02, 6.72791749e-02, ...,
1.29978076e-01, 4.84178978e-04, 3.90726782e-04],
[1.44329050e-03, 6.72923913e-03, 9.73106503e-01, ...,
6.18559401e-03, 5.28032368e-04, 1.72221844e-04],
[9.85002458e-01, 1.17050819e-02, 1.96416397e-03, ...,
5.56563500e-05, 1.91451036e-05, 9.02629108e-06]], dtype=float32), array([[3.1038065e-02, 6.8039525e-01, 2.7858159e-01, ..., 1.8081211e-03,
2.4183639e-04, 6.8499365e-05],
[1.9267431e-01, 3.9702576e-01, 2.6879930e-01, ..., 3.0350521e-02,
3.9923131e-03, 1.0346521e-03],
[9.7498757e-01, 2.2010293e-02, 2.6626829e-03, ..., 5.1270108e-05,
2.0627505e-05, 1.0251430e-05],
...,
[1.0341941e-03, 2.0358764e-02, 7.1253330e-02, ..., 1.3064753e-01,
6.9401663e-04, 2.1888150e-04],
[1.5170611e-03, 9.9281315e-03, 9.6256495e-01, ..., 7.2553097e-03,
4.9441325e-04, 3.0937939e-04],
[9.8283410e-01, 1.3776014e-02, 2.5063211e-03, ..., 6.4137588e-05,
1.7373879e-05, 8.9637824e-06]], dtype=float32), array([[2.2531670e-02, 8.8188958e-01, 8.5531808e-02, ..., 1.0392006e-03,
1.2900545e-04, 4.8717757e-05],
[2.0198147e-01, 3.9738059e-01, 2.6923752e-01, ..., 2.8383162e-02,
4.6745241e-03, 9.1239676e-04],
[9.7342879e-01, 2.4027094e-02, 2.1990994e-03, ..., 7.5795084e-05,
2.8152952e-05, 1.1369398e-05],
...,
[9.3996228e-04, 2.0759458e-02, 9.4039671e-02, ..., 1.5983593e-01,
5.3384079e-04, 2.3209795e-04],
[1.3496265e-03, 1.2265769e-02, 9.7208798e-01, ..., 2.7279316e-03,
4.8197599e-04, 8.0177866e-05],
[9.8314524e-01, 1.4250384e-02, 1.9900955e-03, ..., 6.9334776e-05,
1.9430745e-05, 9.0005724e-06]], dtype=float32), array([[3.0531127e-02, 8.3187169e-01, 1.2173374e-01, ..., 1.5851986e-03,
1.6686841e-04, 6.6045366e-05],
[1.9951424e-01, 3.8786584e-01, 2.6111841e-01, ..., 3.0659745e-02,
7.2425399e-03, 1.0793590e-03],
[9.8361778e-01, 1.3332833e-02, 2.4764170e-03, ..., 1.0251921e-04,
2.4160558e-05, 1.1845524e-05],
...,
[9.6042291e-04, 1.2049039e-02, 9.0317488e-02, ..., 1.6526071e-02,
3.5217035e-04, 1.5015707e-04],
[1.7450673e-03, 1.2770321e-02, 9.6291804e-01, ..., 5.2585122e-03,
5.8553665e-04, 2.4894721e-04],
[9.8440337e-01, 1.3452651e-02, 1.5034712e-03, ..., 4.9955255e-05,
1.9155368e-05, 7.5192124e-06]], dtype=float32), array([[2.8761609e-02, 6.3852876e-01, 3.2233211e-01, ..., 1.8271558e-03,
2.4373706e-04, 6.2998915e-05],
[1.9340727e-01, 3.8923630e-01, 2.6820242e-01, ..., 3.1931452e-02,
8.4003108e-03, 9.6754637e-04],
[9.8404908e-01, 1.3707591e-02, 1.8539022e-03, ..., 5.5987133e-05,
2.1656262e-05, 1.2229758e-05],
...,
[1.1893805e-03, 1.7668687e-02, 9.0628736e-02, ..., 1.1479336e-01,
8.0729101e-04, 2.2969909e-04],
[1.5039227e-03, 9.5729670e-03, 9.6882957e-01, ..., 6.0251877e-03,
3.3653583e-04, 2.1844218e-04],
[9.8510993e-01, 1.3042553e-02, 1.0751045e-03, ..., 5.9135542e-05,
2.6191632e-05, 8.2795732e-06]], dtype=float32), array([[3.32942382e-02, 8.05006862e-01, 1.52579978e-01, ...,
1.27977482e-03, 1.80305477e-04, 6.35773904e-05],
[2.02188164e-01, 3.67901266e-01, 2.82149523e-01, ...,
3.25940177e-02, 9.24468879e-03, 1.04377349e-03],
[9.76144493e-01, 2.03463975e-02, 3.06864991e-03, ...,
6.54720134e-05, 2.36780888e-05, 1.17702202e-05],
...,
[1.03408727e-03, 1.92007311e-02, 1.03628524e-01, ...,
8.78266990e-02, 7.43446290e-04, 1.45116792e-04],
[1.14652608e-03, 6.49474142e-03, 9.77660060e-01, ...,
6.65351376e-03, 4.23836580e-04, 1.07263171e-04],
[9.80339110e-01, 1.63627248e-02, 2.75535043e-03, ...,
6.01201755e-05, 1.92213538e-05, 1.08650265e-05]], dtype=float32), array([[2.1491149e-02, 8.1557244e-01, 1.5412214e-01, ..., 1.6781164e-03,
1.4382144e-04, 5.2884228e-05],
[1.9206944e-01, 3.8720125e-01, 2.8279543e-01, ..., 2.8592097e-02,
9.1844881e-03, 1.0638487e-03],
[9.8905760e-01, 9.4063161e-03, 1.1986574e-03, ..., 5.6440313e-05,
1.2140412e-05, 1.0411514e-05],
...,
[1.0336036e-03, 1.8171517e-02, 9.7263843e-02, ..., 8.0099382e-02,
5.3068146e-04, 3.3236301e-04],
[1.2970228e-03, 7.1522160e-03, 9.6633732e-01, ..., 6.8491558e-03,
4.0542983e-04, 2.1095737e-04],
[9.8446757e-01, 1.1986009e-02, 2.0846534e-03, ..., 6.8975365e-05,
2.4709194e-05, 7.9316414e-06]], dtype=float32), array([[3.50814387e-02, 7.37058461e-01, 2.19399333e-01, ...,
1.24521565e-03, 2.25693264e-04, 7.30693646e-05],
[1.94835052e-01, 3.86061758e-01, 2.77306944e-01, ...,
2.54496094e-02, 8.08648486e-03, 9.73072078e-04],
[9.74543452e-01, 2.29885466e-02, 2.05102284e-03, ...,
7.72189887e-05, 1.80547686e-05, 1.25201814e-05],
...,
[7.66165205e-04, 1.85973272e-02, 6.22044206e-02, ...,
9.76442620e-02, 7.33065128e-04, 2.18284084e-04],
[1.94436137e-03, 1.05775725e-02, 9.72038507e-01, ...,
4.62628435e-03, 3.51657072e-04, 4.19328921e-04],
[9.83149707e-01, 1.34832300e-02, 2.24936288e-03, ...,
6.91555397e-05, 1.80091174e-05, 7.82914412e-06]], dtype=float32), array([[4.1021895e-02, 5.9904146e-01, 3.4779677e-01, ..., 1.0167144e-03,
1.4558017e-04, 6.0799171e-05],
[1.8504380e-01, 3.8665140e-01, 2.8792745e-01, ..., 2.9127903e-02,
7.6887109e-03, 9.7302691e-04],
[9.6933115e-01, 2.6793489e-02, 3.3676450e-03, ..., 6.2180283e-05,
2.9054178e-05, 1.3561730e-05],
...,
[1.0682305e-03, 1.5036174e-02, 7.0086062e-02, ..., 1.4197166e-01,
4.0576013e-04, 2.6423379e-04],
[1.2363504e-03, 7.2964616e-03, 9.6682143e-01, ..., 1.0891506e-02,
6.4196798e-04, 2.4391338e-04],
[9.8594701e-01, 1.0962893e-02, 1.8014964e-03, ..., 5.9777096e-05,
2.1697868e-05, 8.9427258e-06]], dtype=float32)]
LGBMClassifier CV 10회 점수 평균 및 예측
def k_fold_cross_validation2(X, y, k, model, params, test):
skf = StratifiedKFold(n_splits=k, shuffle=True, random_state=42)
macro_f1_scores = []
final_predictions = []
for train_idx, val_idx in tqdm(skf.split(X, y), total=k, desc='Cross Validation Progress'):
X_train, X_val = X[train_idx], X[val_idx]
y_train, y_val = y[train_idx], y[val_idx]
model_instance = model(**params)
model_instance.fit(X_train, y_train, eval_set=[(X_val, y_val)], callbacks=[lgb.early_stopping(100, verbose=False)])
val_predictions = model_instance.predict(X_val)
macro_f1 = f1_score(y_val, val_predictions, average='macro')
macro_f1_scores.append(macro_f1)
xgb_predictions = model_instance.predict_proba(test)
final_predictions.append(xgb_predictions)
mean_macro_f1 = np.mean(macro_f1_scores)
return mean_macro_f1, final_predictions
# Mean Macro F1 Score: 0.8353
lgbm_params1={'objective': 'multiclass', 'metric': 'multi_logloss','boosting_type': 'gbdt', 'num_leaves': 73, 'learning_rate': 0.07228116939428798, 'feature_fraction': 0.9430109139466885,
'bagging_fraction': 0.9815972577904344, 'bagging_freq': 10, 'min_child_samples': 9, 'n_estimators': 436, 'max_depth': 8, 'min_child_weight': 0.002774335258628078, 'subsample': 0.7937163862883831,
'colsample_bytree': 0.8784969823144121, 'reg_alpha': 7.008352155732409e-06, 'reg_lambda': 0.019141374287422526, 'gamma': 0.003215189372648936, 'min_split_gain': 0.00047588264679936733,
'subsample_freq': 7, 'colsample_bylevel': 0.8731399738662942, 'max_bin': 202, 'scale_pos_weight': 6.595555117581444e-07, 'device': 'gpu', 'random_state': 42}
k = 10
lgbm_mean_macro_f1, lgbm_test_predictions = k_fold_cross_validation2(loan_total_prepared, loan_labels, k, lgb.LGBMClassifier, lgbm_params1, test_total_prepared) # 결과 경고 메시지 제거
print(f"Mean Macro F1 Score: {lgbm_mean_macro_f1:.4f}")
print("Mean Test Predictions:")
print(lgbm_test_predictions)
Cross Validation Progress: 100%|███████████████████████████████████████████████████████| 10/10 [07:37<00:00, 45.75s/it]
Mean Macro F1 Score: 0.8353
Mean Test Predictions:
[array([[7.77181891e-03, 8.68573668e-01, 1.21396361e-01, ...,
1.48661132e-04, 4.87138422e-07, 1.13806290e-08],
[2.10731649e-01, 4.36478105e-01, 2.38006824e-01, ...,
2.40049485e-02, 1.15369929e-02, 1.19695092e-04],
[9.76365336e-01, 2.29741369e-02, 5.77840773e-04, ...,
1.55103854e-05, 4.89550933e-08, 1.87134365e-09],
...,
[5.25223033e-05, 3.10323219e-03, 4.33978620e-02, ...,
2.41234045e-01, 6.56250184e-05, 3.15339145e-06],
[8.37178053e-06, 7.58130006e-04, 9.94787264e-01, ...,
8.25034349e-04, 8.06807139e-06, 7.03463845e-07],
[9.96476395e-01, 3.18485882e-03, 2.52186395e-04, ...,
9.89432418e-08, 6.07505794e-09, 1.75846919e-09]]), array([[1.70489004e-03, 9.72857924e-01, 2.50017381e-02, ...,
5.36462620e-05, 4.28490020e-07, 4.29995674e-09],
[2.06980638e-01, 4.34166041e-01, 2.26114967e-01, ...,
3.00166617e-02, 1.06165127e-02, 1.57109149e-05],
[9.79770710e-01, 1.90698492e-02, 1.07979092e-03, ...,
1.27811912e-05, 5.11206754e-08, 1.29159939e-09],
...,
[1.49122943e-05, 6.52288228e-03, 5.60335847e-02, ...,
2.16971027e-01, 4.38515260e-05, 9.99700824e-06],
[5.30126575e-06, 6.49111168e-04, 9.95827787e-01, ...,
1.43709049e-03, 2.11128914e-05, 2.03929839e-06],
[9.94995876e-01, 4.79451793e-03, 1.52843312e-04, ...,
1.84856025e-07, 7.99617755e-09, 9.80461848e-10]]), array([[1.03525619e-02, 9.10298735e-01, 7.72170167e-02, ...,
1.12612966e-04, 1.31083207e-06, 9.58015027e-09],
[2.09120799e-01, 4.23303502e-01, 2.40650935e-01, ...,
2.82416740e-02, 1.30107733e-03, 6.44604052e-05],
[9.93386801e-01, 6.42889471e-03, 1.54495457e-04, ...,
3.82351602e-06, 6.27162642e-08, 2.73543691e-10],
...,
[4.65713398e-05, 2.85158376e-03, 2.51949134e-02, ...,
2.09546161e-01, 4.59106409e-05, 5.91154091e-07],
[1.23687678e-05, 3.54395437e-03, 9.90692685e-01, ...,
1.84874073e-03, 2.15277079e-05, 7.55841845e-07],
[9.89804489e-01, 9.43974371e-03, 3.54732250e-04, ...,
1.83718864e-07, 7.72544121e-09, 8.32597891e-10]]), array([[1.92864990e-02, 9.05700203e-01, 6.88087496e-02, ...,
1.98431152e-04, 9.82560373e-07, 1.09649948e-08],
[2.27066763e-01, 4.18805403e-01, 2.27673616e-01, ...,
3.36418617e-02, 1.06519262e-02, 5.62904930e-05],
[9.76011149e-01, 2.36626647e-02, 2.66955199e-04, ...,
5.23816009e-06, 8.12976750e-08, 2.05205818e-09],
...,
[8.01406485e-05, 2.34038446e-03, 3.32269721e-02, ...,
1.88329971e-01, 3.75224603e-05, 5.69825612e-07],
[2.07738540e-05, 3.14709836e-03, 9.88656170e-01, ...,
4.39328998e-04, 2.71517228e-05, 1.00347123e-06],
[9.94689578e-01, 5.11199653e-03, 1.53097934e-04, ...,
1.28872980e-07, 3.34695486e-09, 5.10308312e-10]]), array([[1.91775750e-02, 8.11623447e-01, 1.66387660e-01, ...,
1.68606894e-04, 6.50214255e-07, 3.79954599e-09],
[2.00517722e-01, 4.18216114e-01, 2.39197697e-01, ...,
3.27326367e-02, 1.25724628e-02, 2.93866086e-05],
[9.80138034e-01, 1.93420334e-02, 4.83846125e-04, ...,
2.66563754e-06, 4.11607475e-08, 1.63739832e-10],
...,
[4.81035987e-05, 3.75362007e-03, 8.02969121e-02, ...,
9.47608475e-03, 2.46316019e-05, 1.65472172e-06],
[8.86551231e-06, 3.34059492e-03, 9.83167922e-01, ...,
2.98714664e-03, 1.45578264e-05, 1.02533600e-06],
[9.97271905e-01, 2.51028276e-03, 6.76008109e-05, ...,
6.69931819e-08, 4.25875349e-09, 2.52809737e-10]]), array([[1.13303472e-02, 9.04227419e-01, 8.26417479e-02, ...,
6.45054738e-05, 1.82378107e-06, 1.94470864e-09],
[1.99010471e-01, 4.16100041e-01, 2.48920535e-01, ...,
2.91147314e-02, 1.24044840e-02, 3.83621502e-05],
[9.88763507e-01, 1.08161961e-02, 4.00106630e-04, ...,
1.74948768e-06, 3.67336199e-08, 1.85810711e-10],
...,
[6.48058354e-05, 2.66607748e-03, 5.09086987e-02, ...,
2.07357042e-02, 1.64511060e-05, 1.08499113e-04],
[1.66132838e-05, 1.22753796e-03, 9.93254722e-01, ...,
1.73348701e-03, 9.49131928e-06, 1.33221654e-06],
[9.94708307e-01, 5.09891363e-03, 1.20584725e-04, ...,
1.20697463e-07, 3.19383811e-09, 1.34107941e-09]]), array([[2.55122861e-02, 8.39260857e-01, 1.31216683e-01, ...,
2.71226288e-04, 6.45800721e-07, 1.70511239e-08],
[2.31164630e-01, 3.96110173e-01, 2.39912858e-01, ...,
3.30128349e-02, 1.28615686e-02, 5.78835403e-05],
[9.87324753e-01, 1.22480405e-02, 3.28259425e-04, ...,
2.65564644e-06, 2.21007798e-07, 9.60791352e-10],
...,
[3.21535754e-05, 2.88913614e-03, 3.98258843e-02, ...,
2.87995833e-02, 2.50898989e-05, 4.45911533e-05],
[1.03587715e-05, 3.29840654e-03, 9.83105363e-01, ...,
1.61425888e-03, 5.58257516e-05, 4.56201813e-07],
[9.95951596e-01, 3.26554102e-03, 7.59672362e-04, ...,
7.78323985e-08, 6.96642452e-10, 3.58193173e-10]]), array([[1.30359928e-02, 9.21936193e-01, 6.19734062e-02, ...,
3.62361613e-04, 2.08731055e-06, 1.18566619e-08],
[1.97271373e-01, 4.33884469e-01, 2.37905823e-01, ...,
3.35216828e-02, 1.20905472e-02, 6.22856769e-05],
[9.88172311e-01, 1.15991244e-02, 1.81598776e-04, ...,
4.26158051e-06, 1.28716339e-08, 5.17471291e-10],
...,
[6.32041551e-05, 2.44770769e-03, 7.68506369e-02, ...,
1.70943003e-02, 3.75497547e-05, 2.89147124e-05],
[3.90621394e-06, 4.82810872e-04, 9.96152884e-01, ...,
3.87016895e-04, 1.22569451e-05, 1.46433680e-06],
[9.95980109e-01, 2.75466901e-03, 1.11454590e-03, ...,
5.34957292e-07, 1.18242023e-08, 3.25173718e-09]]), array([[1.81945114e-02, 8.32086797e-01, 1.46363531e-01, ...,
2.94044152e-04, 3.67258313e-07, 4.96354094e-08],
[2.12073620e-01, 4.23590290e-01, 2.42027213e-01, ...,
1.94496902e-02, 1.24369745e-02, 1.63518064e-04],
[9.83372233e-01, 1.63500676e-02, 2.53582067e-04, ...,
1.95434869e-06, 5.66092030e-09, 4.40892617e-10],
...,
[2.12037726e-05, 2.18108956e-03, 3.09116052e-02, ...,
2.51209260e-01, 2.86499646e-05, 7.01512062e-06],
[1.00122866e-05, 5.55508432e-04, 9.97928861e-01, ...,
6.40245043e-04, 1.54766636e-05, 4.62093313e-06],
[9.92948450e-01, 6.61092360e-03, 2.55179146e-04, ...,
4.11092356e-07, 7.22482448e-09, 1.54009683e-09]]), array([[7.92633394e-03, 9.05040590e-01, 8.49636649e-02, ...,
5.94620899e-05, 2.82592938e-07, 2.31389003e-08],
[1.94038980e-01, 4.33792924e-01, 2.44658237e-01, ...,
2.70318057e-02, 1.27344696e-02, 3.27025813e-05],
[9.84015243e-01, 1.56857021e-02, 2.43468967e-04, ...,
2.72680951e-06, 5.39675639e-08, 5.25884255e-10],
...,
[4.18924043e-05, 4.21319008e-03, 5.06919514e-02, ...,
1.81621466e-01, 2.16322908e-05, 1.75683359e-06],
[1.30504728e-05, 6.40647258e-03, 9.86863441e-01, ...,
1.24389791e-03, 1.23511254e-05, 1.67140646e-06],
[9.96336631e-01, 3.43117161e-03, 6.16584656e-05, ...,
5.05318255e-07, 4.85166382e-09, 6.42765967e-10]])]
4. Submission
def get_submission(prob_list,model_name):
average_probabilities = np.mean(prob_list, axis=0)
final_predictions = []
for proba in average_probabilities:
predicted_label = np.argmax(proba)
final_predictions.append(predicted_label)
submission=pd.read_csv(SUB_DIR)
submission['대출등급']=final_predictions
submission['대출등급'] = submission['대출등급'].map({0:'A',1:'B',2:'C', 3: 'D', 4: 'E', 5: 'F', 6: 'G'})
submission.to_csv(f'{model_name}_submission.csv',index=False)
print(f'Result:{model_name}_submission is saved!')
return submission
sub_xgb = get_submission(xgb_test_predictions,'xgb')
Result:xgb_submission is saved!
sub_lgbm = get_submission(lgbm_test_predictions,'lgbm')
Result:lgbm_submission is saved!
결과
| Submission | CV Macro F1 | Public Macro F1 | Rank | Private Macro F1 | Rank |
|---|---|---|---|---|---|
| 광운인 solution | 0.8353 | 0.84383 | - | 0.84663 | 130/784 |
Lesson
- feature engineering, 하이퍼 파라미터 튜닝를 조금 더 시도할 시간이 있었으면 좋았을 것 같다 (5일 남기고 참가)
- 다음 대회부터는 초기부터 시작해서 더 좋은 성과를 내봐야겠다
